
The Secret Highways of AI: A Friendly Guide to GPU Networking (RoCE, InfiniBand, NVLink & UALink)
Imagine you’re building the world’s most powerful brain. You’re not just using one giant, super-smart neuron; you’re connecting millions of them together, getting them to talk and think as one. That’s essentially what we do when we build systems for Artificial Intelligence (AI).
At the heart of these systems are GPUs, the powerful processors that do the heavy lifting for AI. But a single GPU, no matter how modern and powerful, has its limits. To create the large language models (like the ones powering ChatGPT) or run complex scientific simulations, we need to connect many GPUs together. GPUs must talk to each other faster than CPUs ever needed to. When this communication is slow, your $30,000 GPU only works like it is worth $3,000 GPU.
This is where GPU networking comes in. It’s the invisible infrastructure that allows these computational brains to talk to each other. At Cloudification, we love building powerful, open-source-based solutions for HPC and AI, and in today’s article, we will help you understand the two main types of these super-fast connections.
Think of it like building with LEGO building blocks. You have two ways of connecting them:
- Horizontally: Connecting many separate block towers to build a sprawling city.
- Vertically: Stacking bricks on top of each other to make one very tall, powerful tower.
In the GPU world, we have two corresponding communication technologies: Horizontal and Vertical networking.
| Scope | Connection Type | Technologies |
|---|---|---|
|
Between servers |
Horizontal |
RoCE, InfiniBand |
|
Within one server |
Vertical |
NVLink, UALink |
The Horizontal Connection - Building the City (RoCE vs. InfiniBand)
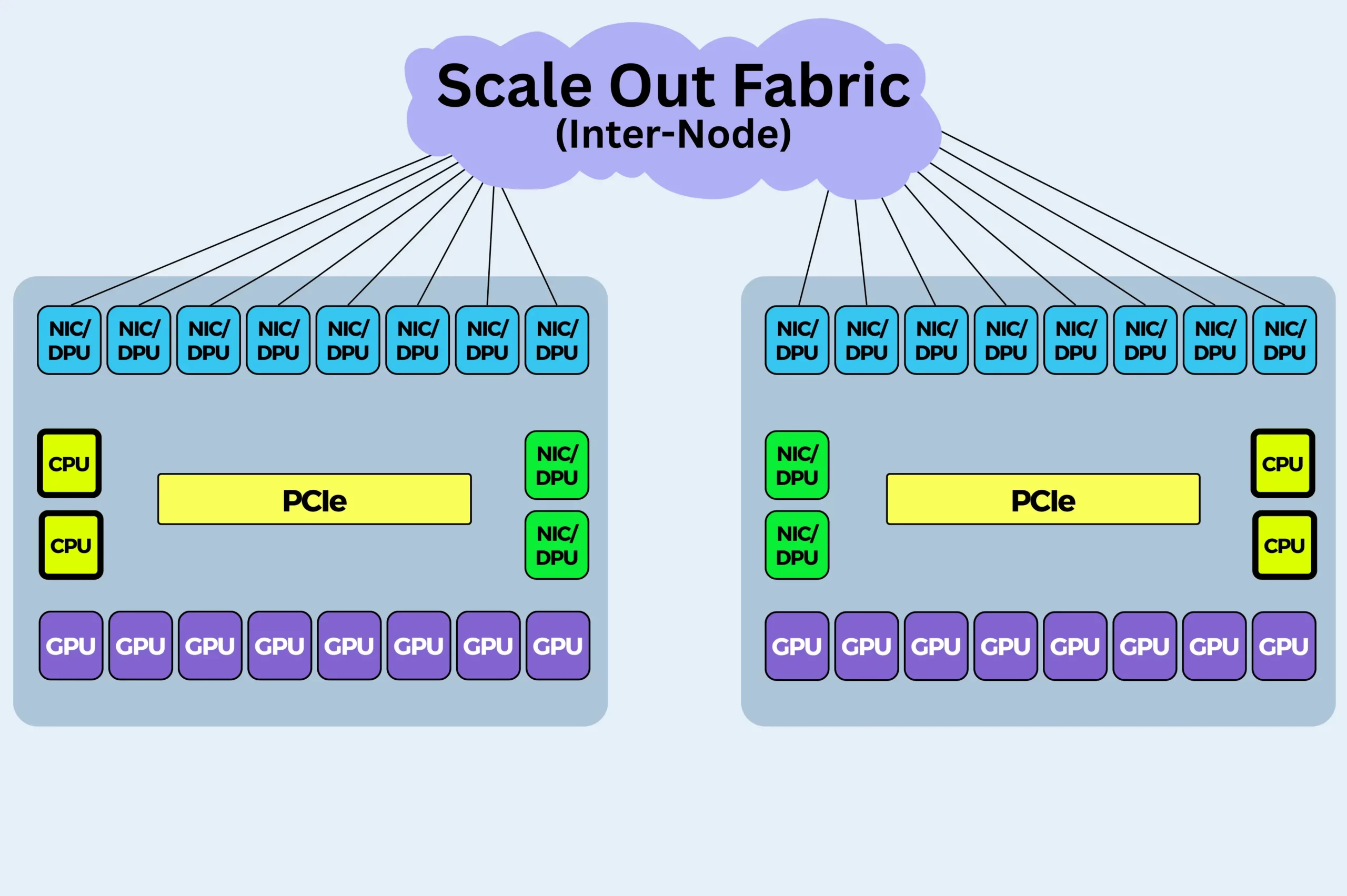
When your AI model gets so big that it doesn’t fit on one computer server, you need to spread it across many. This means connecting multiple servers, each packed with its own GPUs, into a single, powerful cluster. This is horizontal scaling.
For this to work, the network connecting these servers has to be incredibly fast. We’re not just sending emails or web pages; we’re constantly synchronizing the “thoughts” of multiple GPUs. If the network is slow, your expensive GPUs spend all their time waiting for other GPUs instead of calculating, making it a very costly idle time. This is where two major technologies battle it out: RoCE und InfiniBand
RoCE: The Practical, Open-Source Highway
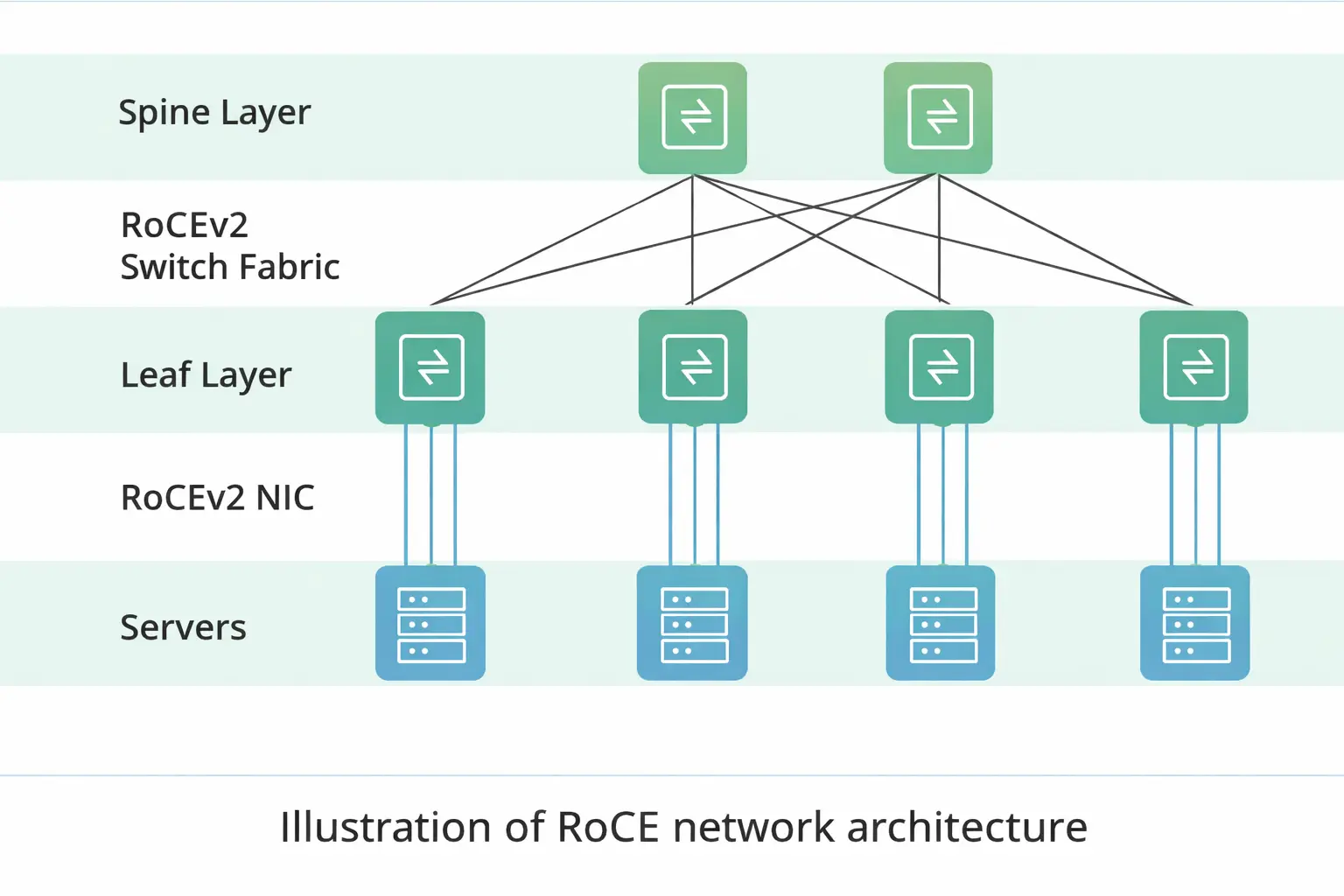
What is RoCE?
RoCE stands for RDMA over Converged Ethernet. Let’s unpack that. RDMA (Remote Direct Memory Access) is a clever trick that allows one computer to access the memory of another directly, skipping the CPUs. It’s like having a direct tunnel between two buildings for packages, bypassing the busy main roads.
RoCE takes this brilliant RDMA concept and puts it on top of Ethernet – the same familiar, widely-used networking technology that powers the internet and most IT networks.
Why is RoCE useful?
- Cost-Effective: Because it uses standard Ethernet, you’re not locked into buying specialized and more expensive equipment.
- Flexible & Open: It’s an open standard, meaning many companies build products for it. This fits perfectly with our love for open-source at Cloudification. You can mix and match components.
- Versatility: It allows you to have one network for both your AI training and your everyday computing tasks, simplifying your data center network architecture.
Where RoCE shines
RoCE is a fantastic choice for many companies. It’s perfect for mid-sized clusters, AI inference (where a model uses its knowledge to answer questions), and scenarios where you want excellent performance without breaking the bank. With careful setup, its performance gets very close to the top dog, InfiniBand.
But don’t just take our word for it. The idea that RoCE is only for smaller deployments was firmly put to rest by Meta. In August 2024, their engineering team published a detailed paper on how they built and operate one of the world’s largest AI networks using RoCEv2. They successfully scaled their RoCE networks from small prototypes to deploying numerous clusters, each accommodating tens of thousands of GPUs. These clusters are the workhorses behind massive production jobs, including training their Llama 3.1 405B model and handling workloads like content recommendation and natural language processing.
Meta’s experience shows that with a sophisticated design—including dedicated backend networks, custom routing schemes (like QP scaling to improve load balancing), and a deep understanding of traffic patterns—RoCE is not just a viable alternative but a powerful, scalable, and reliable foundation for the largest AI training tasks in the world. This proves that for almost any company, RoCE is a contender worth serious consideration.
InfiniBand: An Exclusive, High-Speed Autobahn
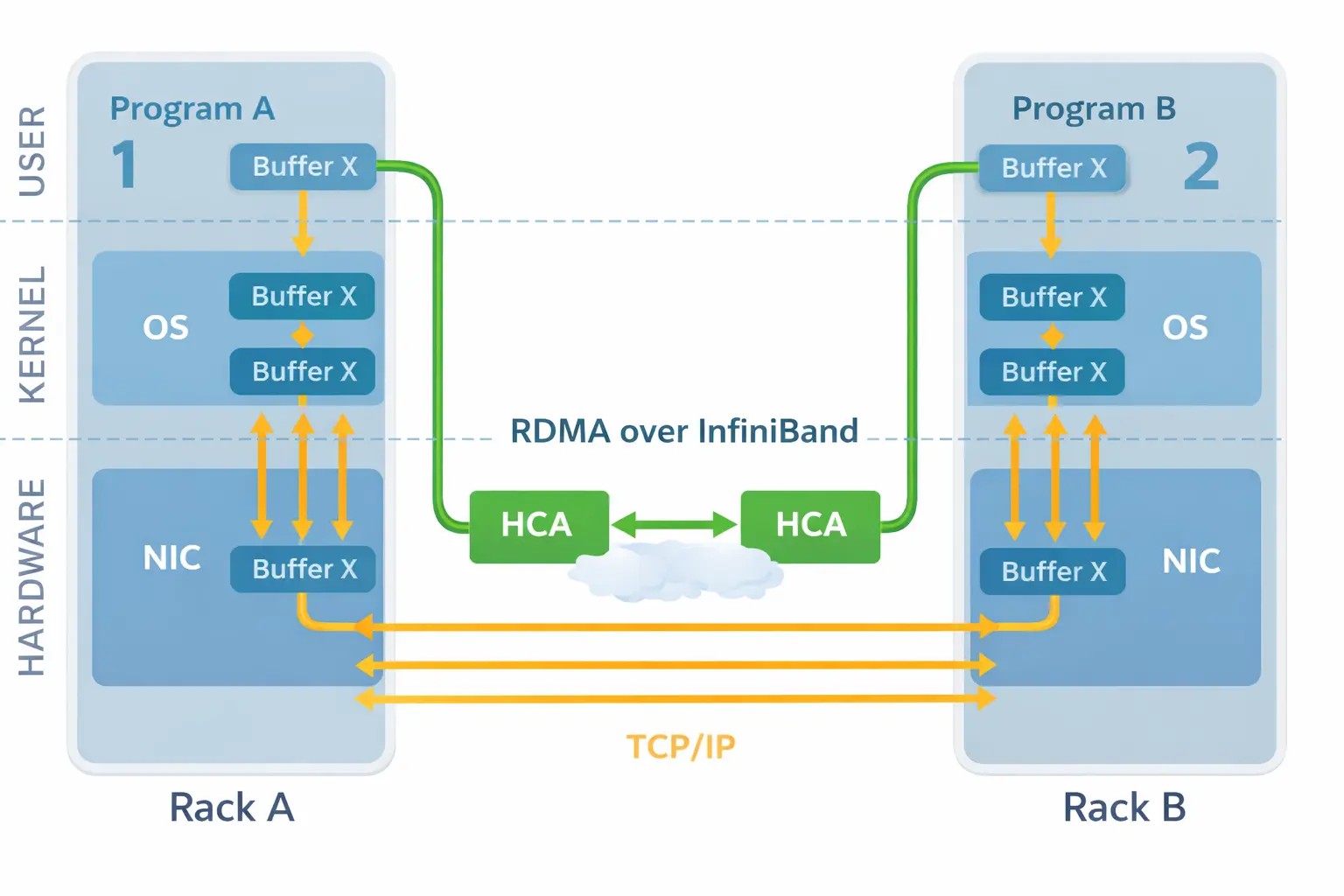
If RoCE is a well-maintained public highway, InfiniBand is a private, purpose-built autobahn designed from the ground up for one thing: sheer, unrelenting speed. It’s a completely separate technology, not built on standard Ethernet.
InfiniBand is a proprietary system, meaning it’s a tightly controlled ecosystem, primarily led by NVIDIA. The hardware, the cables, the protocols—all are designed to work together perfectly to squeeze out every last drop of performance.
Why is InfiniBand useful?
- Unmatched Performance: It offers the lowest latency and the higher bandwidth (incredible data-carrying capacity).
- Built-In Reliability: It has flawless traffic management, ensuring that data packets never get lost or delayed, which is critical when thousands of GPUs are waiting for a single update.
- “It Just Works”: Because it’s a tightly controlled ecosystem, it’s often easier to get peak performance without as much complex tweaking as RoCE sometimes requires.
Where InfiniBand might be better
InfiniBand is often picked for large AI training clusters – including the ones with thousands of GPUs training the most massive models. If your goal is to push the very frontier of AI and budget is less of a concern, this could be your technology.
| Feature |
RoCE (The Open Highway) |
InfiniBand (The Private Autobahn) |
|---|---|---|
|
Technology |
Built on standard Ethernet |
A dedicated, proprietary system |
|
Leistungs- |
Excellent, near top-tier with tuning |
The absolute best, lowest latency |
|
Max Speed (2026) |
Up to 800Gbps (with 1.6T on the horizon) |
Up to 800Gbps (NDR/XDR) , with 1.6T expected post-2026 |
|
Latency |
~300ns with advanced tuning |
Sub-300ns (as low as 200ns) |
|
Cost |
More cost-effective |
More expensive |
|
Ecosystem |
Open, many vendors offering RoCE capable hardware |
Primarily NVIDIA |
|
Best For |
Cost-conscious projects, small clusters, unified data centers |
Performance-obsessed clusters |
The Vertical Connection: Building the Skyscraper (NVLink vs. UALink)
Now, let’s zoom in. Inside a single powerful server, you might have multiple GPUs sitting side-by-side. For the biggest AI models, even the immense memory of one GPU isn’t enough to hold the entire model. You need the GPUs to combine their memory and act as one giant, super-GPU. This is vertical scaling.
This requires a different kind of connection. It has to be mind-bogglingly fast because these GPUs are sharing memory and working on the same problem. We need a “vertical” connection inside the server.
NVLink: NVIDIA's Private Elevator
What is NVLink?
NVLink is NVIDIA’s own, super-high-speed, proprietary connection for linking their GPUs together. It acts like a direct, private elevator between floors in a skyscraper, allowing for instant communication and memory sharing. Its primary goal is to make multiple GPUs function as one seamless, giant accelerator.
NVLink isn’t a static technology; its speed has increased dramatically with each new GPU generation to feed AI’s growing appetite. Here’s how it has evolved:
| NVLink Generation | Key GPU Architecture | Total Bandwidth per GPU | The Breakthrough |
|---|---|---|---|
|
NVLink 1.0 |
Pascal (e.g., P100) |
160 GB/s |
The groundbreaking first step, moving far beyond what PCIe could offer |
|
NVLink 2.0 |
Volta (e.g., V100) |
300 GB/s |
Almost doubled the bandwidth, crucial for the first wave of large AI models |
|
NVLink 3.0 |
Ampere (e.g., A100) |
600 GB/s |
Another massive leap, achieved by increasing the number of links per GPU |
|
NVLink 4.0 |
Hopper (e.g., H100) |
900 GB/s |
Pushed the boundary even further, connecting up to 18 links per GPU |
|
NVLink 5.0 |
Blackwell (e.g., B200) |
1.8 TB/s |
A staggering 2x increase, doubling down on performance for the latest models |
Why NVLink is useful
- Blazing Speed: It’s incredibly fast- with the latest NVLink 5.0 reaching 1.8 terabytes per second (1,800 GB/s), which is well over 2x faster than even the best 800Gbps horizontal network connections (like RoCE or InfiniBand). This allows multiple GPUs to operate as one seamless unit.
- Memory Sharing: This is the key feature. GPUs can directly access each other’s memory, effectively pooling their resources to handle colossal models that wouldn’t fit on a single card.
Where do you need NVLink?
If you’re working with truly massive language models and need to spread them across multiple GPUs in a single server, NVLink is the gold standard. It’s an essential part of NVIDIA’s DGX systems and HGX platforms.
DGX is NVIDIA’s own turnkey AI supercomputer – like the new DGX GB200 (NVL72) which connects 72 GPUs in a single rack-scale system. HGX, by contrast, is the reference design NVIDIA provides to partners like Dell and HPE, typically featuring eight GPUs on a single board (e.g., H100 or Blackwell).
Think of HGX as the “guts” inside most enterprise AI servers, and DGX as the complete, ready-to-run appliance. Both rely on NVLink to make multiple GPUs act as one giant accelerator.
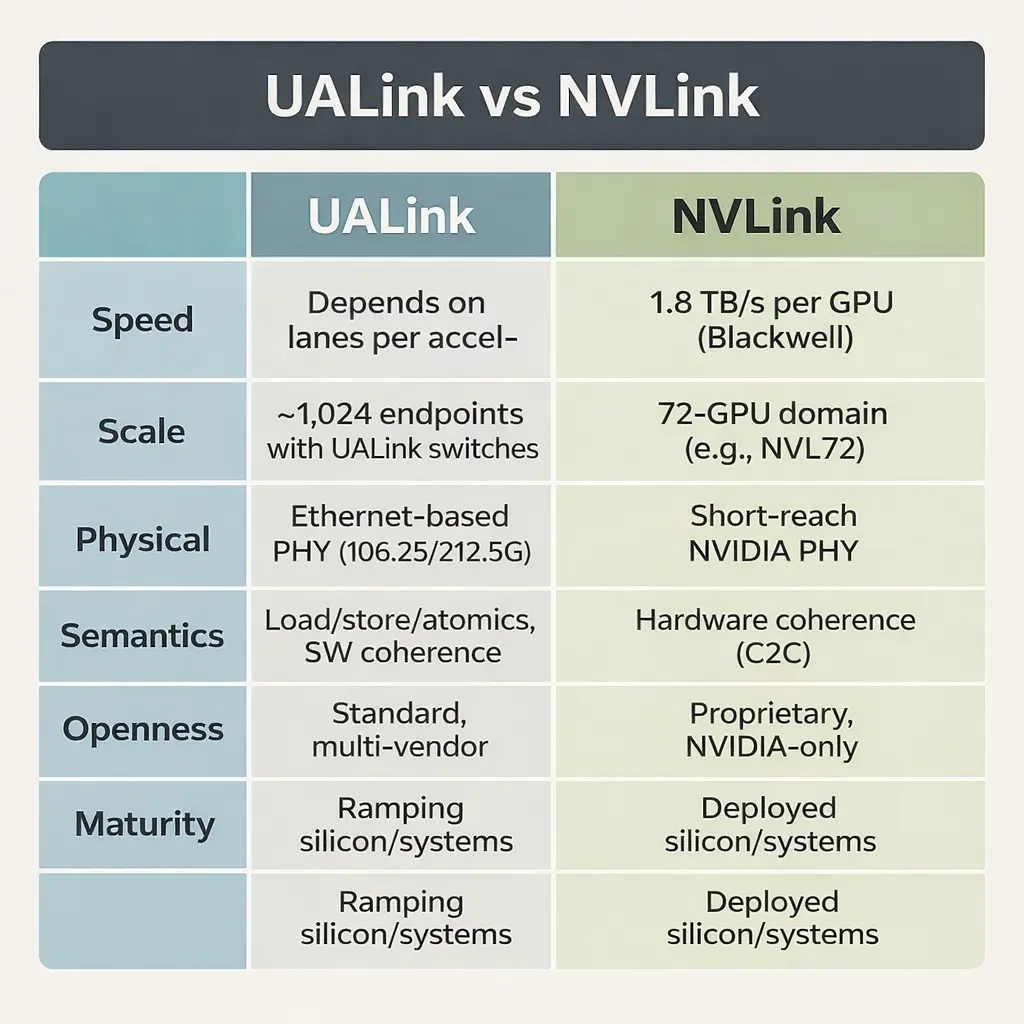
UALink: The New Open Standard Challenger
What is UALink?
For a long time, NVLink was the only game in town. But a consortium of tech giants (including AMD, Intel, Google, and Meta) got together to create an open alternative called UALink or Ultra Accelerator Link.
Think of it as a group of companies building their own high-speed elevator system that anyone can use, breaking NVIDIA’s monopoly on this technology.
Why UALink is useful
- Open and Interoperable: It allows GPUs and other accelerators from different companies (like AMD or Intel) to connect with each other just as tightly as NVIDIA.
- Avoiding Lock-In: It gives companies a choice. They are not forced to use only NVIDIA products to build the most powerful AI servers.
Where does UALinkit fit?
UALink is the future. The first hardware is expected around late 2026 or 2027. It will be crucial for data centers that want to build flexible, multi-vendor AI infrastructures without being tied to a single company’s ecosystem.
| Feature |
NVLink (Private Elevator) |
UALink (Open Elevator) |
|---|---|---|
|
Technology |
Proprietary (NVIDIA) |
Open Consortium (AMD, Intel, Google, etc.) |
|
Leistungs- |
The current peak |
Designed to be highly competitive |
|
Max Speed (2026) |
Up to 1.8 TB/s per GPU (NVLink 5.0 in Blackwell) |
Up to 800 GB/s per GPU (UALink 1.0, 4 lanes × 200G) |
|
Max Cluster Size |
576 GPUs in a single NVLink domain |
1,024 accelerators in a single fabric |
|
Goal |
Create the ultimate NVIDIA-only system |
Create an open, multi-vendor alternative |
|
Availability |
Available since 2014 and currently in 5.0 generation |
Expected in late 2026/2027 |
So, What Does This Mean for You?
This all might sound like rocket science, and for the people not building these systems daily, it often is. The key takeaway is that networking is not an afterthought; it is the foundation of modern AI.
Here’s the simple truth:
- If you’re just starting with AI or have smaller models, you might not need any of this special networking. You might be able to start with a single powerful server depending on your requirements.
- If you’re scaling up and need to connect a few servers, a well-designed RoCE network offers a fantastic balance of performance and cost without vendor-lock.
- If you’re building a massive AI supercomputer with thousands of GPUs to train the next generation of world models, you might be looking at InfiniBand and NVLink.
- If you value open standards and flexibility and are planning for the future, keep a close eye on UALink development.
Building Your AI Future with Cloudification
At Cloudification, we don’t just watch these trends; we help you navigate them. We are experts in building powerful, scalable, and cost-effective cloud solutions with a passion for open-source technologies.
This means we are perfectly positioned to help you design and deploy RoCE-based high-performance computing (HPC) and AI clusters. We can help you get 90% of the way to InfiniBand performance at a lower cost, using the flexible, open technology that aligns with our philosophy.
The future of AI is being built on these secret highways. Let us help you build yours. Contact us today to start your journey.