c12n
HPC Cloud Lösungen
Hohe Leistung
- Dedizierte GPU oder vGPU
- NVIDIA MIG und Kubernetes Operator
- Lokaler NVMe- und Ceph-Storage
Niedrige Latenz
- Echtzeit-Linux-Kernel
- Time-Sensitive Networking (TSN)
- Smart NICs mit RDMA/RoCE
Maximale Skalierung
- Cloud-Nativ von Grund auf
- Flexibles Workload-Scheduling
- Skalierbar auf Hunderte von Nodes
VM- oder Container-basierte HPC Cloud


Für Multitenancy und
maximale Workload-Isolierung 🔒
Für Single-Tenant und
native Bare-Metal-Performance ⚡
-
VMs mit KVM-Hypervisor
Der weltweit meistgenutzte Open-Source-Hypervisor vom Typ 1
-
Software-Defined Networking
Virtuelles Routing, Floating IPs,
Firewall und NAT -
Block- / Objekt- / lokaler Storage
3-fach replizierte, redundante Storage-Optionen
-
PCI-Passthrough für TSN und GPUs
SR-IOV, Virtual Functions (VF) und
dedizierte Geräte -
Dynamisches und konfigurierbares Scheduling
Ressourcenzuweisung basierend auf Last und Fähigkeiten
-
NVIDIA AI Enterprise Support
Modernste Tools für Inferenz, Training und Machine Learning
-
Container mit Containerd CRI
Leichtgewichtige, industriestandardisierte Container-Runtime
-
Cilium CNI
Hochperformantes eBPF-basiertes CNI mit integrierten Sicherheitsfunktionen
-
Block- / Objekt- / lokaler Storage
3-fach replizierte, redundante Storage-Optionen
-
K8s Device Plugin
Für GPUs, NICs, FPGAs oder nichtflüchtigen Hauptspeicher
-
Dynamisches und konfigurierbares Scheduling
Ressourcenzuweisung basierend auf Last und Fähigkeiten
-
NVIDIA Kubernetes GPU Operator
Node-Labeling, Monitoring, Container-Tools und mehr
HPC Cloud Lösungen für KI-Zeiten
MAßGESCHNEIDERT FÜR IHREN USE-CASENvidia vGPU & MIG
Betreiben Sie dedizierte GPUs, virtuelle GPUs und Multi-Instance GPUs, inklusive des Nvidia Kubernetes Operators.
Local NVMe & SDS
1.000.000+ IOPS für anspruchsvollste Anwendungen sowie flexible Software-Defined-Storage-Optionen (Block, Object, File)
SLURM, PyTorch, TensorFlow, Jupyter and more
Betreiben Sie die beliebtesten Frameworks und Workload-Management-Systeme mit Leichtigkeit
High-speed Network with RDMA
Dedizierte Frontend-, Backend- und Storage-Netzwerke für maximale Performance und starke Isolation
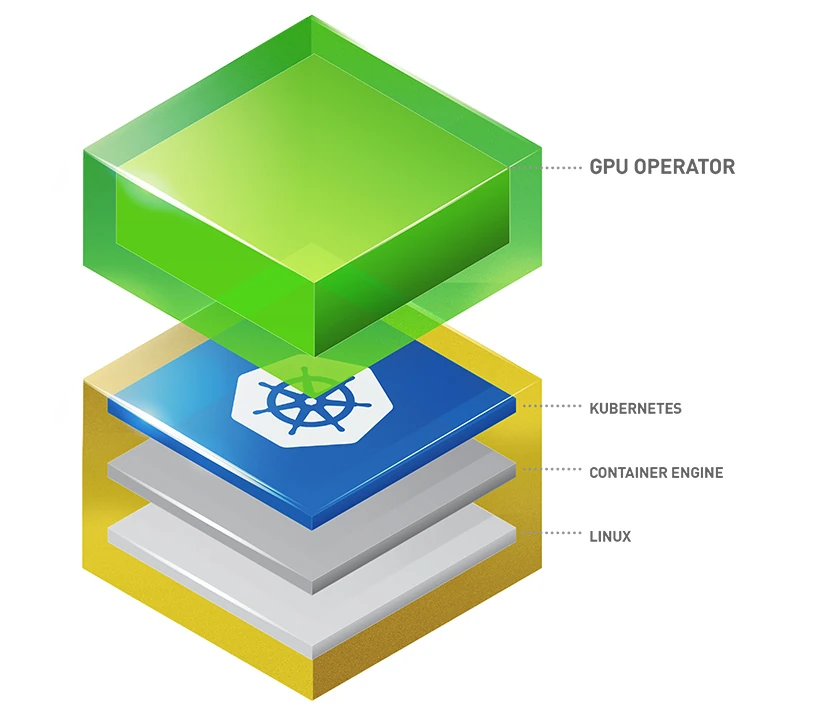
NVIDIA Multi-Instance GPU (MIG)
Teilen Sie GPU-Ressourcen effizient mithilfe von MIG ohne NVIDIA AI Enterprise Lizenz auf Kubernetes-Clustern mit GPU Operator.
NVIDIA A100, A30, L40, H100 und H200 GPUs können bis zu 7-fach partitioniert werden, wobei jede Partition jederzeit garantierte Ressourcen erhält.
Die gleiche Partitionierung ist auch mit vGPU in VMs möglich, erfordert jedoch eine NVIDIA AI Enterprise Lizenz.Ältere GRID-vGPU-Lizenzen werden nicht unterstützt.
Block-, Objekt- und Share Storage mit Rook-Ceph
Ceph ist ein verteiltes, hochverfügbares, softwaredefiniertes Storage-System, das eine S3-API für Objektspeicher, Block-Storage-Geräte sowie NFS/SMB-Freigaben bereitstellt.
Die Architektur von Ceph ist selbstverwaltend und selbstheilend. Mithilfe des CRUSH-Algorithmus (Controlled Replication Under Scalable Hashing wird die Datenplatzierung im Cluster bestimmt. Ceph stellt Daten bei einem Laufwerks- oder Knotenausfall automatisch wieder her und gleicht sie neu aus.
Ceph, zusammen mit dem Rook -Operator und Kubernetes , bildet eine leistungsstarke und hochskalierbare Speicherlösung, die Petabytes an Daten speichern kann.

Beliebte Deep Learning Frameworks & Tools
ZU IHREN DIENSTEN 🧑🔧
PyTorch ist ein Open-Source-ML-Framework auf Basis von Python und der Torch-Bibliothek. Ursprünglich von Meta AI entwickelt, wird es heute häufig für Computer Vision und Natural Language Processing eingesetzt. PyTorch unterstützt eine Vielzahl neuronaler Netzarchitekturen – von einfacher linearer Regression bis hin zu komplexen Convolutional Neural Networks und generativen Transformer-Modellen.

TensorFlow ist eine Open-Source-Plattform und ein Framework für Machine Learning und künstliche Intelligenz, entwickelt zum Trainieren und und Inferieren neuronaler Netze mit Daten. Ursprünglich von Google entwickelt, erleichtert TensorFlow die Erstellung von ML-Modellen, die in jeder Umgebung mit allen gängigen Programmiersprachen (Python, JavaScript, C++ und Java) laufen können. TensorFlow kann mehrere CPUs und GPUs effektiv nutzen.

Jupyter ist ein Open-Source-Projekt für interaktives Rechnen über mehrere Programmiersprachen hinweg und entstand ursprünglich aus IPython im Jahr 2014. Jupyter Notebooks ermöglichen Echtzeit-Codeergebnisse und und -Bilderund können Eingaben/Ausgaben in beliebiger Reihenfolge ausführen. Diese Funktionen machen es zu einem nützlichen Werkzeug für schnelles Prototyping, die Gestaltung von Code-Präsentationen oder die mühelose Unterstützung von Data-Science-Workflows.
Auf der Suche nach geeigneter HPC Hardware?
Mit Hilfe unserer Partner entwerfen wir eine optimale Hardware-Spezifikation passend zu Ihren Anforderungen und Ihrem Budget. Wir liefern,, installieren und verkabeln alle Server- und Netzwerktechnik in der DACH-Region und meisten EU-Ländern.Eine vollständige End-to-End-HPC-Cloud-Lösung über den gesamten Lebenszyklus für Ihre KI- und ML-Workloads.
Häufig gestellte Fragen (FAQ)
BEANTWORTET 👇Erhalte ich den c12n.hpc-Quellcode?
Ja! ✅
Eine vollständige GitOps-Konfiguration für das gesamte Infrastruktur-Setup wird in Ihrem Git-Repository in Ihrem eigenen Infrastruktur gespeichert. Der Quellcode aller eingesetzten Komponenten ist öffentlich zugänglich.
Zusätzlich empfehlen wir, alle benötigten Docker-Images zu spiegeln. Falls noch nicht vorhanden, richten wir einen Git-Server sowie eine lokale Container-Registry ein.
Welche Hardware kann verwendet werden?
Es können Hardware-Komponenten beliebiger Hersteller verwendet und sogar innerhalb eines Clusters gemischt werden. Sowohl Intel- als auch AMD-CPUs sowie GPUs von NVIDIA, AMD oder Intel werden unterstützt. Falls Sie neue Hardware anschaffen möchten, beziehen wir gerne unseren vertrauenswürdigen Hardware-Partner mit ein, um ein optimales Preis-Leistungs-Setup für Ihr Szenario zu entwickeln.
Kann Cloudification Hardware in unserem Rechenzentrum installieren?
Ja! ✅
Kontaktieren Sie uns für weitere Details.
Kann c12n.hpc andere Storage-Lösungen statt Ceph verwenden?
Ja! ✅
Wir verfügen über umfangreiche Erfahrung in der Integration und im Betrieb von NetApp und Pure-Storage mit OpenStack und Kubernetes sowie in der Implementierung von Treibern für herstellerspezifische Storage-Lösungen in OpenStack.
Zusätzlich unterstützen wir lokalen RAID-Storage sowohl für OpenStack- als auch für Kubernetes-Deployments.
Kann c12n.hpc für SLURM-Cluster verwendet werden?
Ja! ✅
Wir empfehlen jedoch, wann immer möglich Container und Kubernetes zu nutzen.
Kann c12n.hpc für OpenHPC eingesetzt werden?
Ja! ✅
Auf Wunsch erstellen wir auch vorgefertigte VM- oder Container-Images mit den gewünschten Software-Versionen.
Kann eine c12n.hpc-Installation vollständig air-gapped betrieben werden?
Ja! ✅
Für die Erstinstallation benötigen wir jedoch Remote-Zugriff.
Gibt es proaktives Monitoring & Alerting?
Ja! ✅
Wir können c12n-Monitoring auch in Drittanbieter-Lösungen für On-Call-Dienste und Slack oder andere Messenger integrieren.
Im Falle bestehender Supportvereinbarungen werden alle kritischen Alarme innerhalb der vertraglichen SLAs bearbeitet.
Gibt es einen Logging-Service?
Ja! ✅
Basierend auf OpenSearch -Projekt und alle Logs von allen Knoten und Diensten im Cluster werden automatisch gesammelt. Dies umfasst Audit-, Kernel-, Kubernetes-, OpenStack-, Ceph- und andere Logs.
Optional können wir auf Anfrage ElasticSearch (ELK-Stack) integrieren.
Schlüsselfertige Cloud Lösung
Durchgängig automatisierte, überwachte und sichere Multi-Purpose-Cloud-Plattform für HPC-, AI- und ML-Workloads
Was gibt's Neues in der Cloud?
SCHAUEN SIE IN UNSEREM BLOG VORBEI 👇HPC Computing leicht gemacht mit c12n.hpc
Erleben Sie vollständig gemanagte, skalierbare HPC-Lösungen für moderne AI, GPU und ML Workloads.
