
Kubernetes anti-patterns:
What NOT to do
It’s no secret that here at Cloudification we are passionate about Kubernetes, we love writing about it and sharing with you all its upsides, features and all the things you can do with it.
But we think it is equally important to talk about all the things you definitely should not do when using K8s to avoid unnecessary complications and headaches. So, today we’re addressing K8s anti-patterns.
These are high-risk and ineffective practices disguised as solutions that end up costing extra time and resources when having to go back to fix them. Here is our pick of the Top 11 Kubernetes Anti-Patterns that you should avoid at all cost.
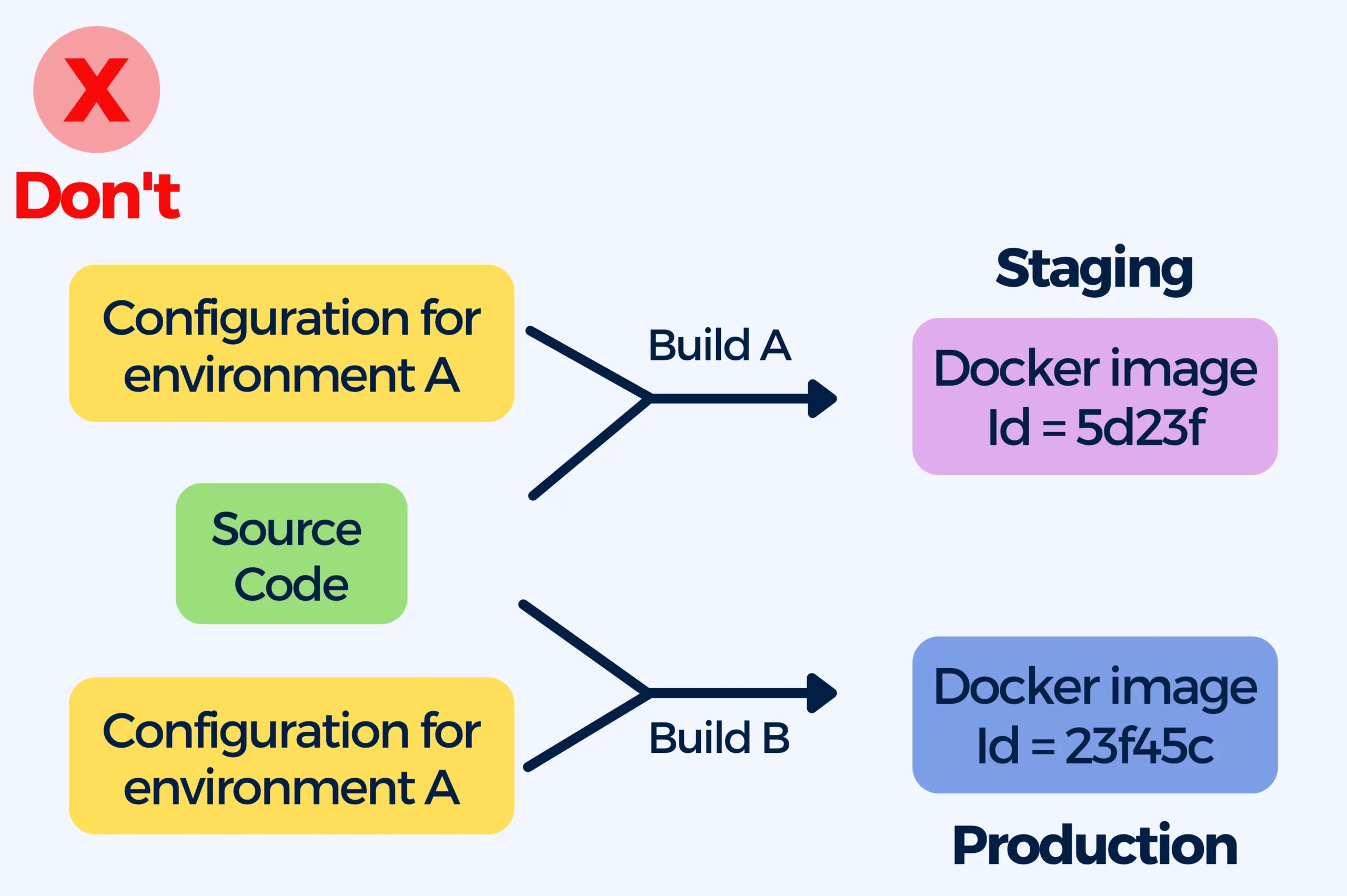
1. Baking the configuration inside container images
Containers allow developers to use a single image through the lifecycle in the production environment.
You want your images to be able to run in any environment, and you can achieve that by building them once and then promoting them from one environment to another. There should not be configuration present in the container itself.
However, people commonly make the mistake of giving each phase in the lifecycle (QA, staging, or production) its own image.
The problem when each image is built with different artifacts specific to its environment, is that you won’t be deploying what you’ve tested and you will have to rebuild your image so you deploy to production something different than what was tested previously.
You know you have built environment-dependent container image when your container image:
- has hardcoded IP addresses
- contains passwords and secrets
- mentions specific URLs to other services
- Is tagged with strings such as “dev”, “qa”, “production”
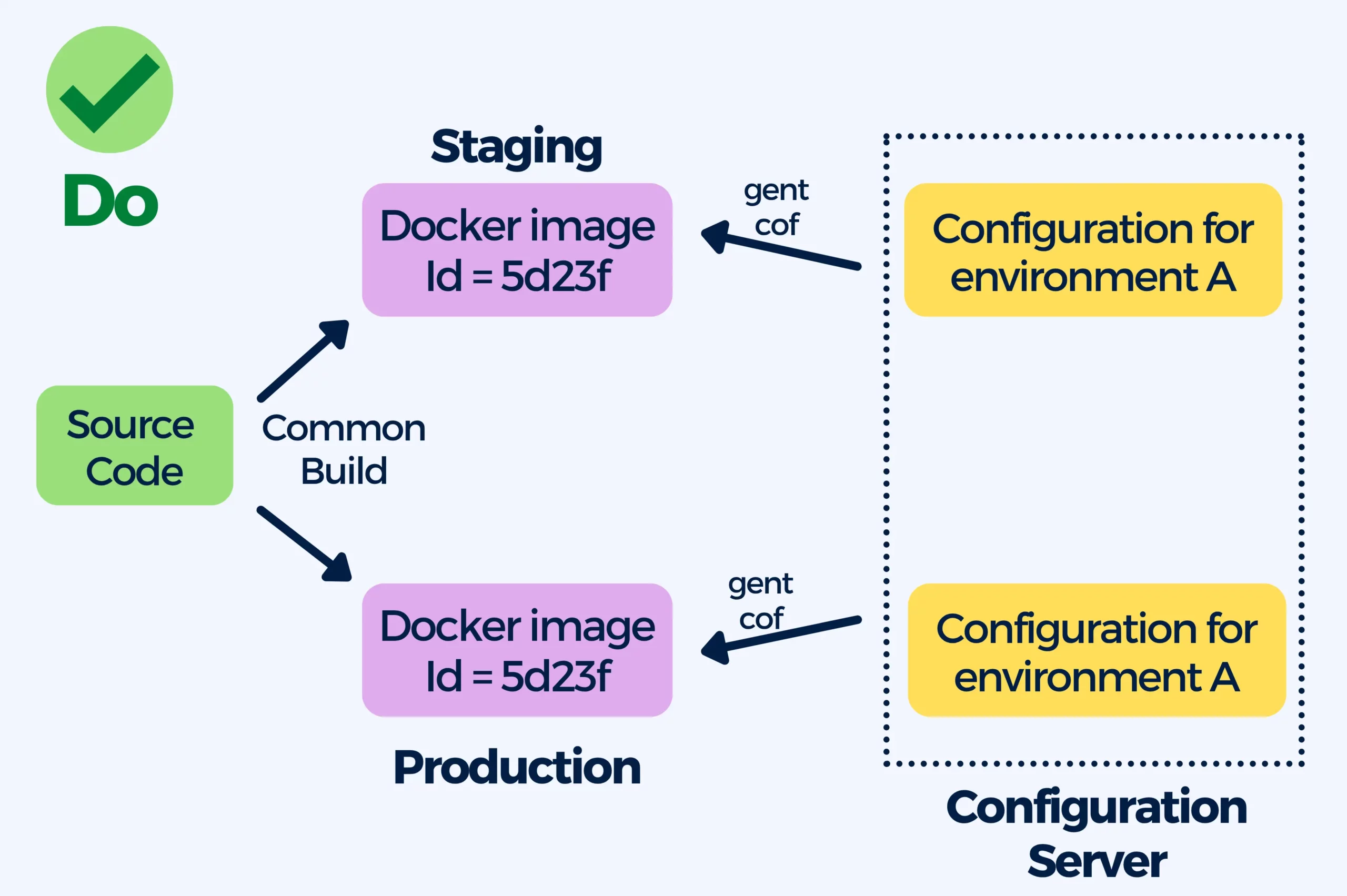
The best practice here is to create (generic) images that are able to run in any environment, your images should be independent of the environment they are running on. To achieve this you can externalize general-purpose configuration in Kubernetes Configmaps, use Helm or Kustomize. Containers allow you to use a single image through the entire software lifecycle.
The benefit of this practice is having a single image that can be deployed in all your environments making it much easier to understand what it contains and how it was created.
Furthermore, this saves you time by eliminating the need to change the configuration on your cluster, instead of rebuilding the full container image from scratch you can simply change the external configuration system. In some cases, you can even update the live configuration without any restarts or redeployments.
2. Mixing application deployment with infrastructure deployment (e.g. having IaC deploying apps with the Helm provider)
Infrastructure as code (IaC) allows you to define and deploy infrastructure in the same way as writing software code. Being able to deploy infrastructure in a pipeline can be useful, as long as infrastructure and application deployment are not done together.
It is a common mistake to create a single pipeline that creates both infrastructure (i.e. creating a Kubernetes cluster, container registry, etc.) to later deploy an application on top of it.
In theory, this might sound like a good way to go, but in reality it ends up causing a lot of resource and time waste as it means you are starting from scratch with each deployment.
More often than not, the application code changes much faster than the infrastructure. A pipeline that deploys everything takes much longer than a pipeline that deploys only the application. You end up wasting time on each deployment because you create and destroy the infrastructure when the infrastructure has not changed.
If a pipeline deploys everything (infra + app) and takes about 30 minutes where application takes only 5 minutes, that means 25 minutes are being wasted on each deployment when the infrastructure has not changed.
Moreover, if that one pipeline breaks, it is not clear who must look at it. You might need to deal with IaC errors, network issues, or the application itself. And if developers are forced to deal with infrastructure when they don’t need to, then the purpose of DevOps, which is to empower developers with self-service tools, is basically defeated.
The best way to go is splitting deployment of infrastructure and applications into their own pipelines. This will result in faster application deployments, plus the infrastructure pipeline will not be triggered as often as the application one. The need to deal with infrastructure errors or understand how the Kubernetes cluster was created when the application pipeline breaks is eliminated and operators can fine-tune infrastructure pipelines without bothering developers at all.
3. Deploying things in a specific order
Applications shouldn’t crash because a dependency isn’t ready.
Having a specific order to the startup and stop tasks when bringing up applications is something we can see in traditional deployments. However, it is crucial not to bring this practice into container orchestration. With Kubernetes and containers these components start simultaneously and it is impossible to define a startup order. Application dependencies could fail or be migrated when they are running, which should not introduce problems.
Poor network latency can cause communication failures where dependencies can’t be reached, during which a pod might crash or a service might become unavailable. The best practice is to anticipate failures and lay down frameworks that help avoid downtime and data lost, for example:
- Implement a retry pattern with features like:
- Cancel: The application should cancel the operation and report an exception if the process is unlikely to be successful on repeated attempts.
- Retry: When it is unlikely that the same error will reoccur, the application should retry the request immediately.
- Retry after delay: When the failure is caused by connectivity or busy failures, the application should wait before retrying the request.
- Implementing a circuit-breaking pattern for cases when retrying doesn’t work (for example with a Service Mesh).
- You can use Helm Chart and Init containers to wait for all dependencies before starting Kubernetes Pods.
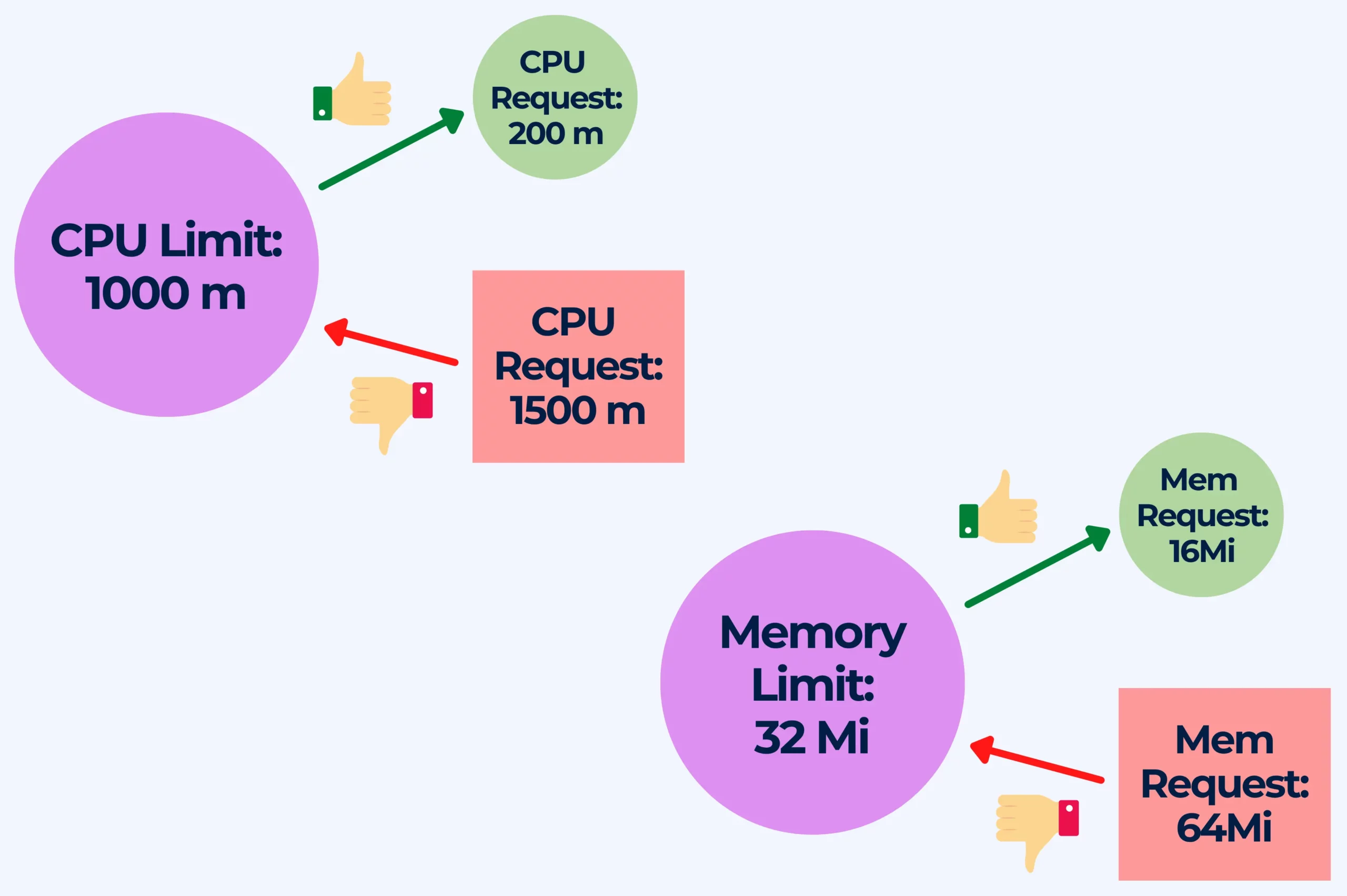
4. Deploying pods without memory and/or CPU limits set
Resource allocation differs depending on the service, and it can be complicated to predict what resources a container might require for optimal performance without prior testing. One service could require a fixed CPU and memory consumption profile, while another service’s consumption profile could be dynamic.
What you should NOT do:
- Deploying pods without specifying a memory or CPU limit for a container
- Request more resources than the limit when setting the memory and CPU resources for a container
Falling into these anti-pattern can cause resource contention, unstable environments, overcommitment of resources, node and kubelet failures.
Without memory or CPU limits the scheduler assumes that the memory and CPU utilization is close to zero. Furthermore, a large number of pods can be scheduled on any node and a container could use all of the available memory on its node, possibly invoking the OOM (out of memory) killer.
Not setting memory or CPU limits causes the default memory limit of the namespace (in which the container is running) is assigned to the container. The best way to avoid this issue is by declaring memory and CPU limits for the containers in your cluster so that the use of the resources available on your cluster’s nodes is efficient. This way, the K8s scheduler will be able to determine on which node the pod should reside for most efficient hardware utilization.
You should also tune the requests based on monitoring metrics. If the aggregate resource requests exceed the set limit(s) in pods that have more than one container, the pod will never be scheduled. By setting memory and CPU requests below their limits you make sure that the pod can make use of memory/CPU when it is available, which leads to bursts of activity. Keeping the CPU requests at a reasonable number of cores, and then using Deployment replicas to scale apps horizontally, will ensure system stability.
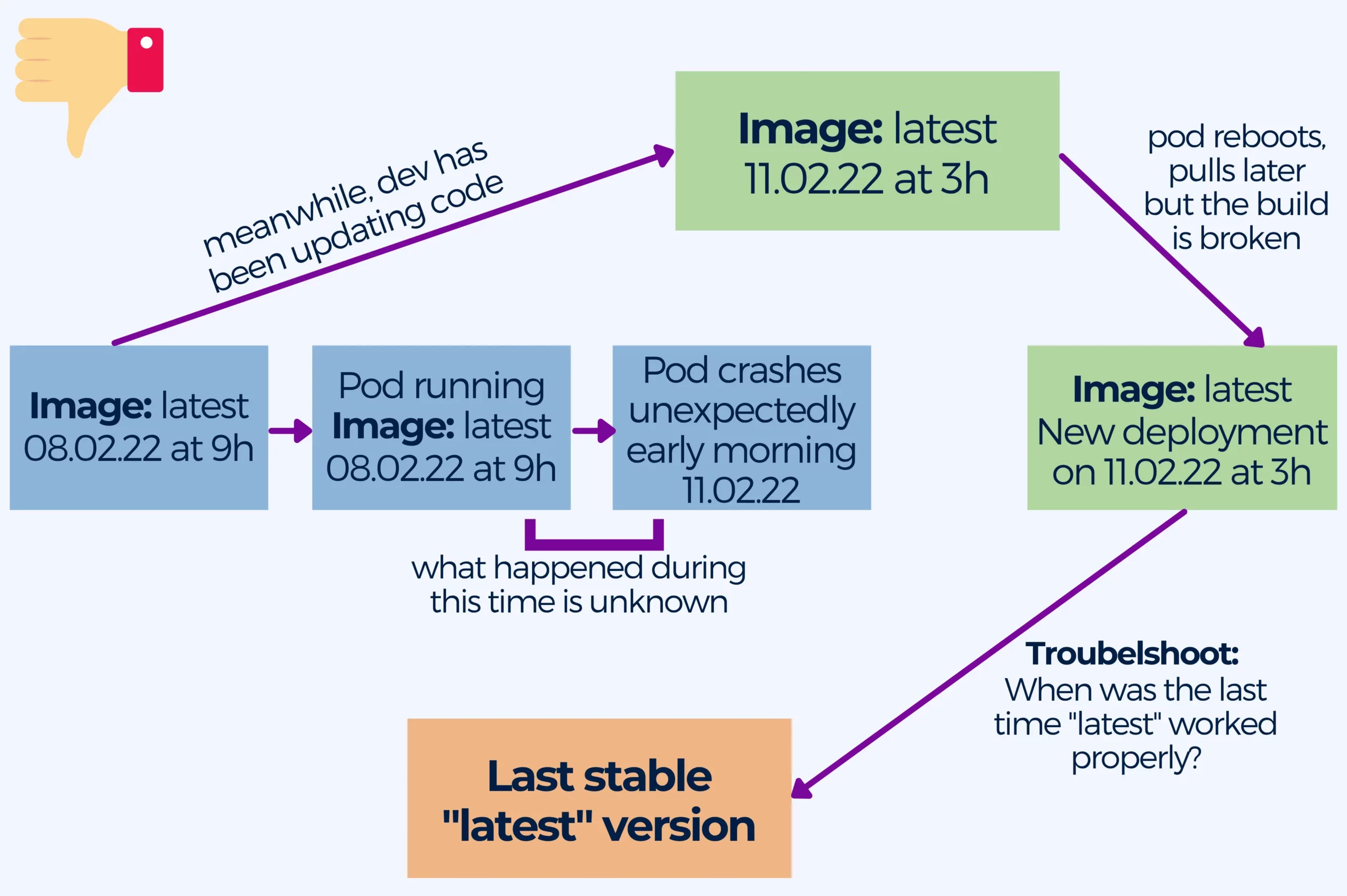
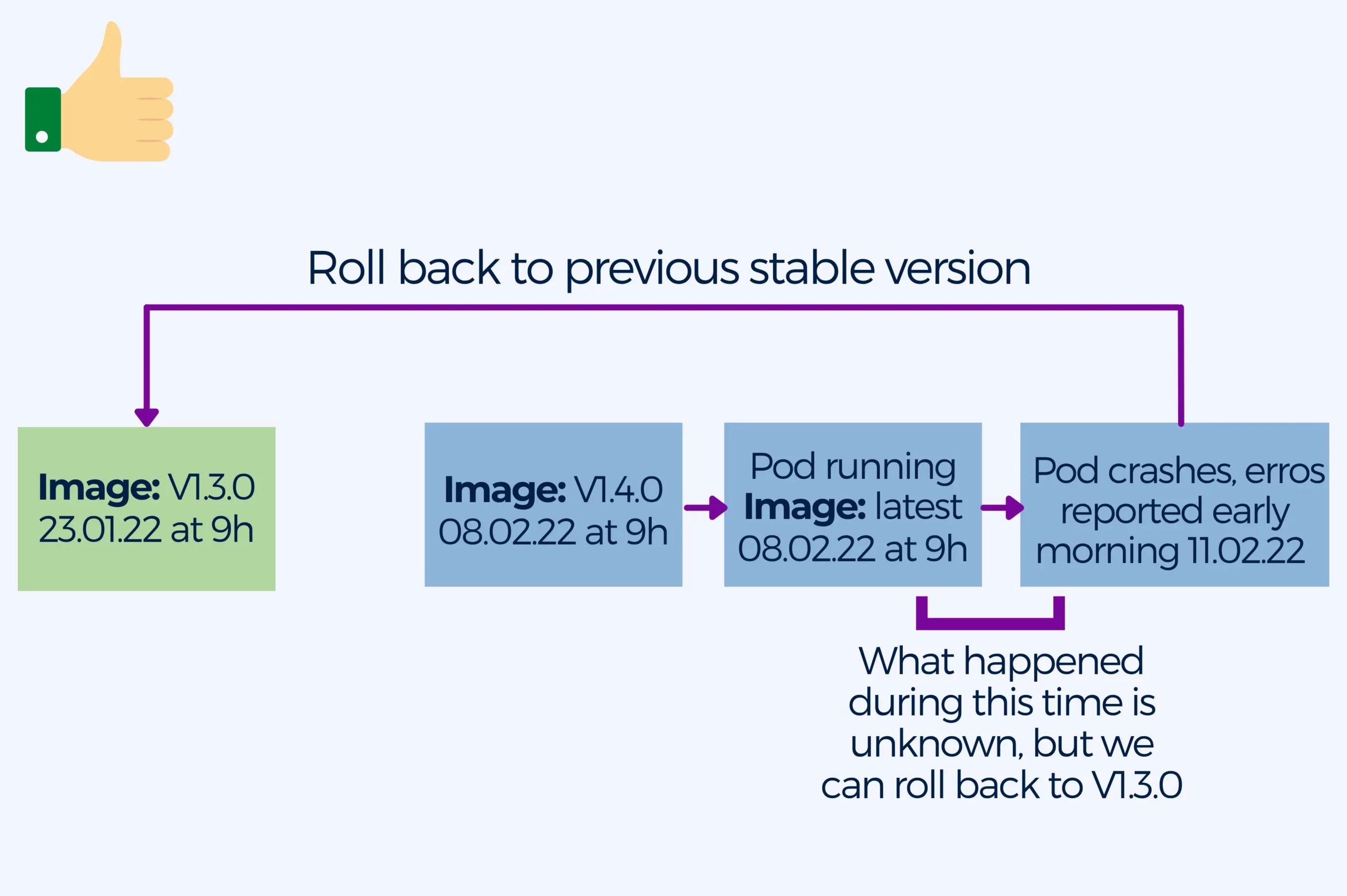
5. Pulling the latest tag in containers in production
One of the most common anti-patterns is using the latest tag, especially in production.
It is not uncommon for pods to crash inadvertently, pulling down images at any time. And when this happens, the latest tag is not very descriptive when it comes to pinpointing when the build broke, what version of the image was running, or when was the last time it was working. This lack of information is particularly bad in production, when you want to keep the downtime to a minimum until you manage to get things back up and running.
If the imagePullPolicy is set to Always, K8s will always pull down the image when it restarts. If you don’t specify a tag, Kubernetes will default to latest.
Even if you changed the imagePullPolicy to a value different from Always, your pod might still pull an image if it needs to restart for any reason.
The best practice is to use specific and meaningful image tags, possibly date and time of the build. At the same time you should keep your container images immutable. It is recommendable to store any data outside containers in persistent storage. Remember not to modify a container once you spin it up. Deploy a new container with the updated config provided by a ConfigMap when you need to update the configuration.
As a result you will benefit from safer and repeatable deployments, rolling back when you need to redeploy the old image becomes easier and you can deploy the same container image in every environment knowing it will work.
6. Running production and non-production workloads in the same cluster
Using a single cluster for all your needs is not a good idea, even when Kubernetes is specifically designed for cluster orchestration. Having at the very least two clusters, a production one and a non-production one is essential even if you are a small startup.
Mixing production and non-production workloads is not good for resource starvation. A rogue development version can transgress on the resources of a production version.
Even more importantly, security problems can arise because by default all communication inside a Kubernetes cluster is allowed. Some Kubernetes resources are not namespaced and a pod from one namespace can communicate with a pod in another namespace unless restricted by NetworkPolicies.
Supporting multi-tenancy inside a cluster and securing all workloads against each other is complicated and can be fatal when combined with other anti-patterns. Kubernetes namespaces are not a security measure and it is much easier to create a second cluster exclusively for production.
The best practice here is to ALWAYS have at least two clusters (1 production + 1 non-production).
The bigger the project, the more clusters might be needed such as:
- Production
- Shadow/clone of production but with less resources
- Developer clusters for feature testing (see the previous section)
- Specialized cluster for load testing/security (see previous section)
- User acceptance testing (UAT)
- Cluster for internal tools
7. Not using blue/green or canaries for mission-critical deployments.
(Default rolling update of Kubernetes might not be enough)
Having little to zero downtime for change deployments is the goal for application owners. For most mission-critical applications zero downtime is a must. With Kubernetes you can define Recreate and RollingUpdate deployment strategies. Recreate will kill all the Pods before creating new ones, while RollingUpdate will update Pods in a rolling fashion and permit configuring maxUnavailable and maxSurge to control the process.
The Anti-pattern here is using only default deployment strategies plus not using blue/green or canaries for mission-critical deployments.
The problem here is that deployment strategies have the following limitations:
- Recreate: kills all Pods before creating new ones, causes downtime
- RollingUpdate: updates Pods in a rolling fashion and allows configuring maxUnavailable and maxSurge to control the process, yet can make rollback harder
Furthermore, there is no rapid experimentation and feedback on new versions of the services and mission-critical applications require zero downtime for deployments. Best practice here is to use blue/green or canaries for mission-critical deployments to increase service reliability and enable rapid development.
blue/green deployment means copies of your application created, where the old (blue) and new (green) version, where both services run in parallel. It keeps the old version up and running while releasing the new version and route all production traffic to it. The old version can be used in case there are issues, preventing downtime and can be removed when no longer needed.
Canary deployment routes the traffic to the new service only for a subset of users. You can introduce a new version of your service in production while monitoring it closely and you can release the new version to more or all users once everything is running smoothly.
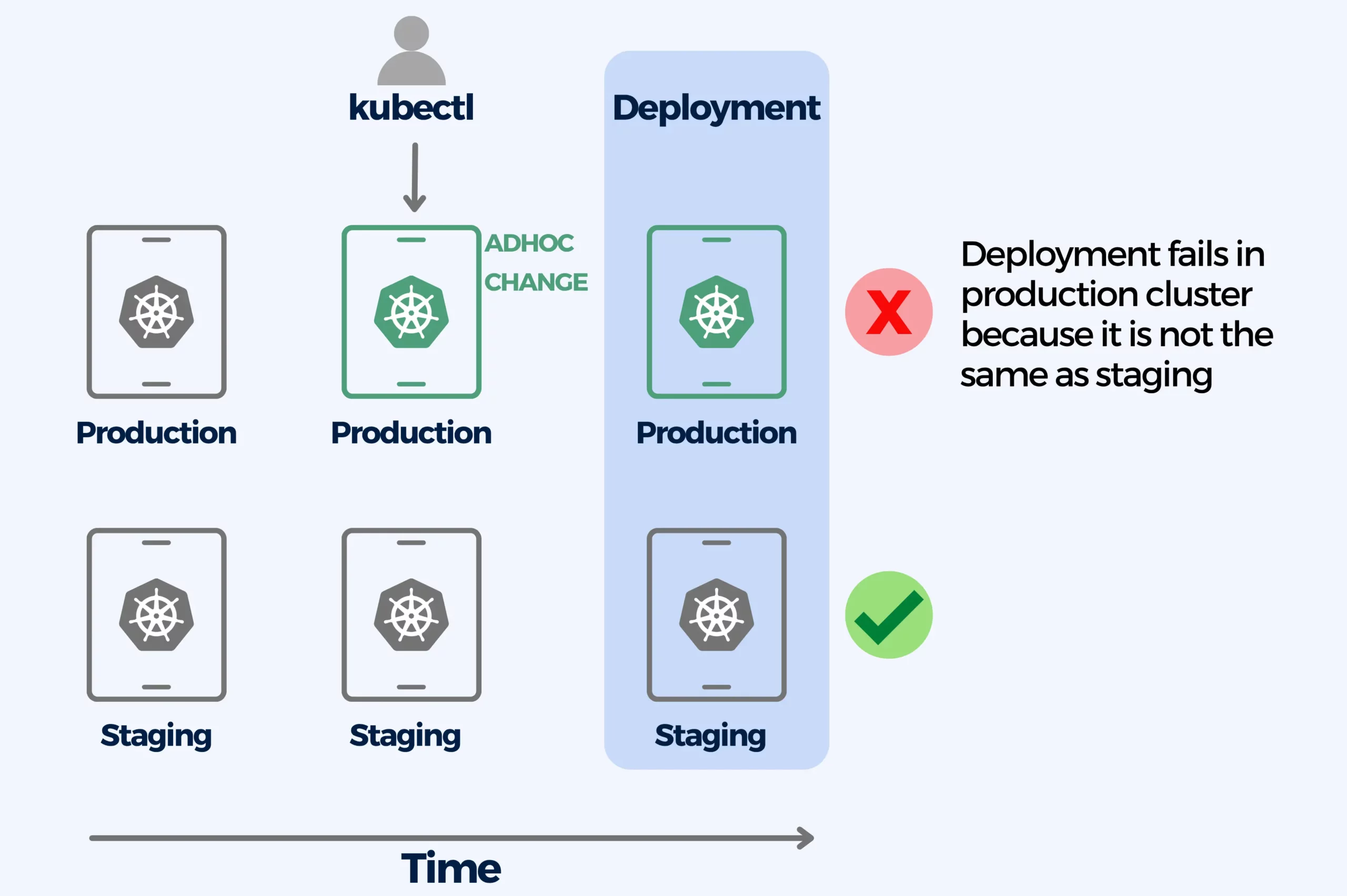
8. Performing ad-hoc deployments with kubectl edit/patch by hand
Using kubectl for deployments by hand causes configuration drift. Configuration drift happens when two or more environments are supposed to be the same, but after certain changes or ad-hoc deployments they stop having the same configuration. This problem can escalate to the point where a machine’s configuration is lost and has to be reverse-engineered from the live instance.
The kubectl CLI can change resources in place on a live cluster thanks to its built-in apply/edit/patch commands. But when ad-hoc changes in the cluster are not recorded anywhere else
Environment configurations are a very recurrent cause for failed deployments. A production deployment that worked in the staging environment will still fail afterwards if the configuration of the two environments is not the same anymore.
This is why you should never change live resources on a production cluster by hand. Instead, you should use a deployment platform that will take care of it and it should also be recorded in Git. Following the GitOps paradigm is recommended.
Deployments via a Git commit:
- You have a complete history of what happened in your cluster and what is contained in each one at any point in time.
- You know how environments differ among themselves.
- Git configuration allows you to recreate or clone an environment from scratch.
- Rolling back configuration is trivial as you can simply point your cluster to a previous commit.
Furthermore, the patch/edit capabilities of kubectl should only be used for debugging or development. You will be able to rapidly spot the last change that affected a deployment and its configuration in case it fails.
9. Lack of Health Checks, not using Liveness and Readiness probes for pods
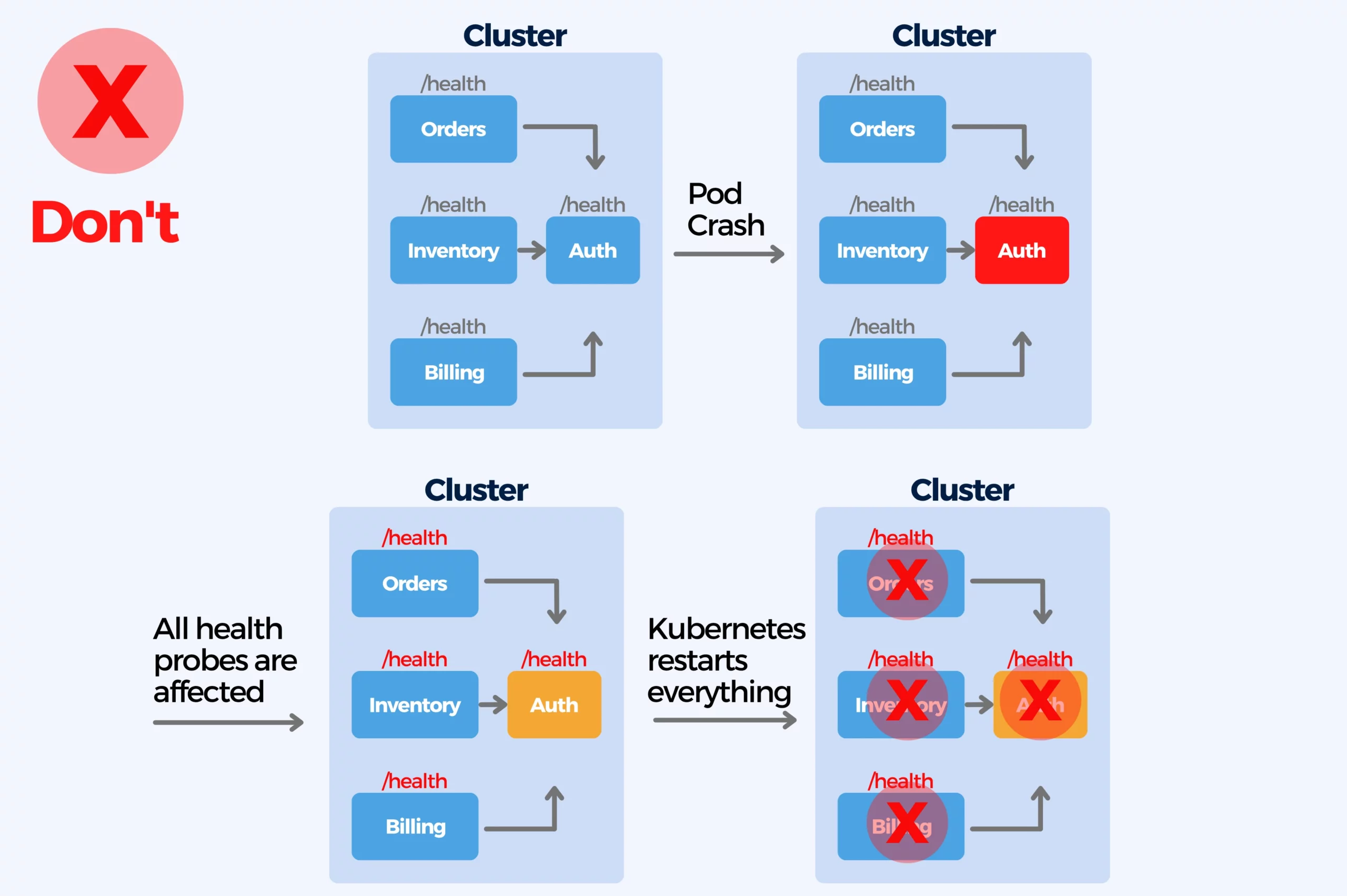
Not performing health checks can cause a lot of problems. A health check is necessary to validate the status of a service and to assess key information like service availability, system metrics, or available database connections. But creating too complex health checks with unpredictable timings (that cause internal denial of service attacks inside the cluster) can become a problem too.
A service can report its status through health endpoints like /health, /livez, or /readyz. Kubernetes supports Container probes (livenessProbe, readinessProbe, startupProbe) that allow monitoring services and take actions when the probe is successful.
Kubernetes health probes have to be set up per each container, it has none by default. Health probes are as essential for Kubernetes deployments as having resource limits. All applications should have at least liveness and readiness when deployed in any cluster of any type. Health probes decide when and if your application is ready to accept traffic and allow to take actions when the probe is successful.
- Startup probe: runs only once and checks the initial boot of your applications.
- Readiness probe: runs all the time and checks if your application can respond to traffic. If it fails, Kubernetes will stop routing traffic to your app (and will retry later).
- Liveness probe: runs all the time and checks if your application is in a proper working state. If it fails, Kubernetes will assume that your app is stuck and will restart it by killing the pod .
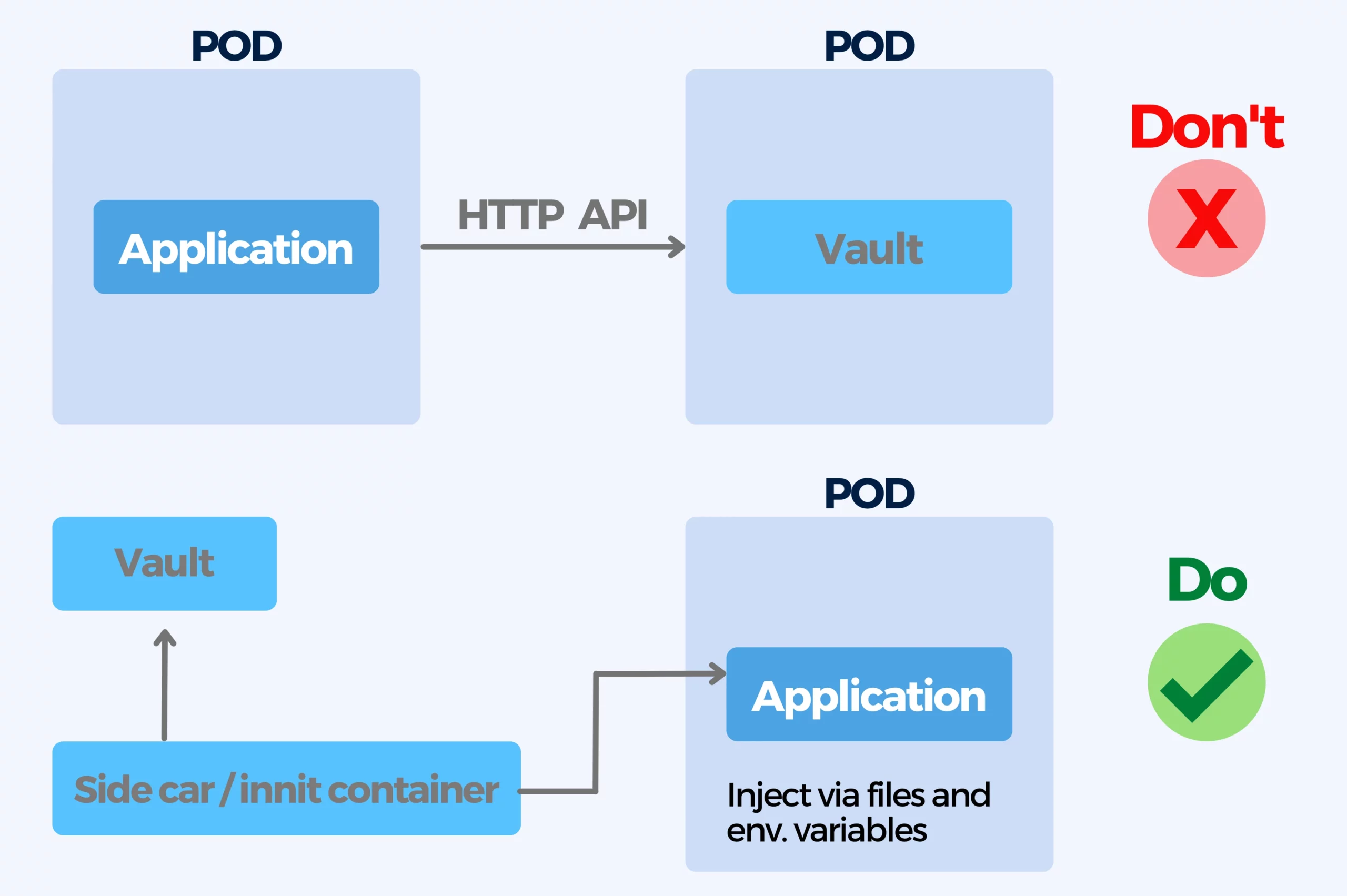
10. Not implementing a secret handling and not using Vault
Baking configuration in containers is bad practice, especially when it comes to secrets. There are different approaches to secret handling that go from storage to git (in an encrypted form, for instance with git-crypt) to a full secret solution like Hashicorp Vault. Secrets should be passed during runtime to containers.
When it comes to secret handling you should avoid using multiple ways for secret handling, confusing runtime secrets with build secrets or using complex secret injection mechanisms that complicate local development and testing.
For handling secrets make sure you use the same (or similar) service that you use for configuration changes, it is crucial to pick a secret handling strategy and use the same for all applications. A possible solution is using Hashicorp Vault.
All secrets from all environments should be handled the same way and passed to containers during runtime. It is essential to know the difference between runtime and build secrets and pass only the necessary secrets to each application:
- Runtime secrets: needed AFTER app deployment (e.g. database passwords, SSL certificates, private keys, etc.)
- Build secrets: needed ONLY while the app is packaged (e.g. credentials to the artifact repository or for file storage). These secrets are not needed in production and should never be sent to a Kubernetes cluster!
Handling secret management in a flexible way, allows for easy testing and local deployment.
11. Running multiple processes per container and not using controllers
Pods are the smallest deployable units of computing that you can create and manage in Kubernetes. Kubernetes Pod is a building block that itself is not durable.
Pods should not be used directly in production because they won’t get rescheduled, retain their data or guarantee any durability. Running multiple processes/applications in one container of a Pod and running Pods without controllers like Deployment or Job are big mistakes.
This can cause problems like secondary processes exiting or crashing silently in containers and not being auto-restarted.
The best strategy is to use Deployment with replication factor, which will guarantee that pods will get rescheduled and will survive eviction or node loss.
You should also define one process per container and use multiple containers per Pod if needed to run related processes together. It is also helpful to create Pods using workload resources such as Deployment , Job or StatefulSet (to store state persistently) and to use replication factor of Deployment to add more pod replicas and scale your application horizontally.
Anti-Pattern: Using background processes
$ cd prod/background
$ docker build -t $(minikube ip):5000/background:0.0.1 .
$ docker push $(minikube ip):5000/background:0.0.1
$ kubectl create -f crash.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
crash 1/1 Running 0 5sThe container appears to be running, but let’s check if our server is running there:
$ kubectl exec -ti crash /bin/bash
root@crash:/#
root@crash:/#
root@crash:/# ps uax
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 21748 1596 ? Ss 00:17 0:00 /bin/bash /start.sh
root 6 0.0 0.0 5916 612 ? S 00:17 0:00 sleep 100000
root 7 0.0 0.0 21924 2044 ? Ss 00:18 0:00 /bin/bash
root 11 0.0 0.0 19180 1296 ? R+ 00:18 0:00 ps uax
root@crash:/#Wrapping Up
Kubernetes is a powerful and flexible platform—but with great power comes great responsibility. While it offers incredible capabilities for scaling, managing, and deploying applications, it also opens the door to a variety of pitfalls if not used correctly. By avoiding these 11 anti-patterns, you can ensure your clusters remain secure, performant, and maintainable.
Whether you’re new to Kubernetes or running large-scale clusters in production, keeping these common mistakes in mind will help you get the most out of your infrastructure while avoiding unnecessary pain down the road.
🚀 Ready to level up your Kubernetes game?
At Cloudification, we help teams build better cloud-native architectures—without the drama. If you’re struggling with Kubernetes complexity, need help with container orchestration, or want to avoid these anti-patterns altogether, get in touch with us for a consultation.
👉 And if you found this article helpful, don’t forget to share it with your team and follow us on LinkedIn for more practical tips and deep dives into cloud-native tech.
Happy deploying! 🧑🚀🌥️