c12n
HPC Cloud Solutions
High Performance
- Dedicated GPU or vGPU
- Nvidia MIG and K8s Operator
- Local NVMe and Ceph Storage
Low Latency
- Real-Time Linux Kernel
- Time-Sensitive Networking (TSN)
- Smart NICs with RDMA/RoCE
Maximum Scale
- Cloud-Native by Design
- Flexible Workload Scheduling
- Scaleable to 100-s of nodes
VM or Container- Based Cloud HPC


For multitenancy and
maximum workload isolation🔒
For single tenant and
native baremetal performance⚡
-
VMs with KVM Hypervisor
The most popular type 1 open source hypervisor
-
Software Defined Networking
Virtual Routing, Floating IPs, Firewall and NAT
-
Block / Object / Local Storage
3-way replicated redundant storage options
-
PCI Passthrough for TSN and GPU
SR-IOV, Virtual Functions (VF) and dedicated devices
-
Dynamic and configurable Scheduling
Allocate resources based on load and capabilities
-
Nvidia AI Enterprise Support
State of the art tools for Inference, Training and ML
-
Containers with Containerd CRI
Lightweight, industry-standard container runtime
-
Cilium CNI
High performance eBPF CNI with security features
-
Block / Object / Local Storage
3-way replicated redundant storage options
-
K8s Device Plugin
For GPUs, NICs, FPGAs, or non-volatile main memory
-
Dynamic and configurable Scheduling
Allocate resources based on load and capabilities
-
Nvidia Kubernetes GPU Operator
Node labeling, monitoring, container tools and more
HPC Cloud Solutions for AI Era
TAILORED TO YOUR USE CASENvidia vGPU & MIG
Run dedicated GPU, virtual GPU and Multi-Instance GPU including Nvidia Kubernetes Operator
Local NVMe & SDS
1.000.000+ IOPS for most demanding applications and flexible Software Defined Storage options (block, object, share)
SLURM, PyTorch, TensorFlow, Jupyter and more
Run the most popular frameworks and workload management systems with ease
High-speed Network with RDMA
Dedicated front-end, back-end, storage networks for maximum performance and strong isolation
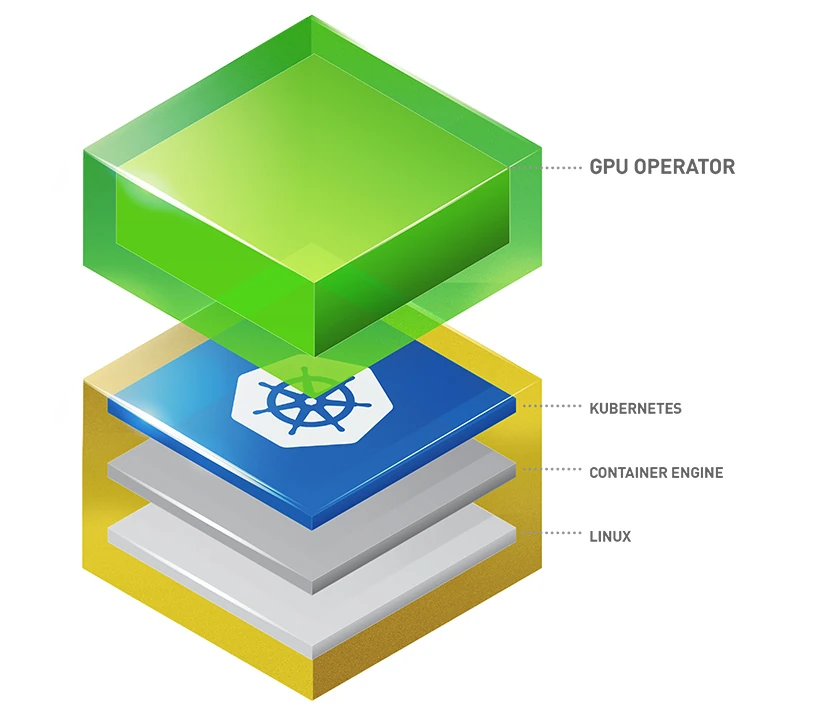
NVIDIA Multi-Instance (MIG)
Share GPU resources efficiently using MIG without Nvidia AI Enterprise license on Kubernetes cluster with GPU operator. Nvidia A100, A30, L40, H100, H200 GPU models can be partitioned up to 7 times with each partition having guaranteed slice of resources available at all times.
Same partitioning can be done with vGPU in VMs, but it requires Nvidia AI Enterprise license. The older GRID vGPU licenses cannot be used.
Block, Object and Share Storage with Rook-Ceph
Ceph is a distributed, highly-available software defined storage system that provides S3 API for object storage, block storage devices and NFS/SMB shares.
Ceph’s architecture is designed to be self-managed and self-healing. It uses Controlled Replication Under Scalable Hashing (CRUSH) algorithm to determine the placement of data across the cluster. Ceph will automatically recover and re-balance the data in case of a failed drive or node.
Ceph, together with Rook operator and Kubernetes makes a powerful and highly scaleable storage solution capable of storing PB of data.

Popular Deep Learning Frameworks & Tools
AT YOUR SERVICE 🧑🔧
PyTorch is an open-source ML framework based on Python and the Torch library. Originally developed by Meta AI, it is commonly used for computer vision and natural language processing today. PyTorch supports a wide variety of neural network architectures, from simple linear regression algorithms to complex convolutional neural networks and generative transformer models.

TensorFlow is an open-source platform and framework for machine learning and artificial intelligence, designed to train and infer neural networks on data. Originally developed by Google, TensorFlow makes it easy to create ML models that can run in any environment with all most popular programming languages supported (Python, JavaScript, C++, and Java). TensorFlow can effectively utilize multiple CPUs and GPUs.

Jupyter is an open-source project for interactive computing across multiple programming languages that started from IPython back in 2014. Jupyter Notebooks allow real-time code results and imagery, and can execute input/outputs in any order. Those features made it a useful tool for quick prototyping, designing code presentations or facilitating data science workflows with ease.
Looking for a suitable HPC hardware?
With a help of our partner we will design optimal hardware specification for your requirements and budget. We can further deliver, install and cable all servers and network equipment in DACH region and most of EU countries. A full lifecycle end-to-end HPC cloud solution for your AI and ML workloads.
Frequently Asked Questions
ANSWERED 👇Do I get the c12n.hpc source code?
Yes! ✅
A complete GitOps configuration for the whole infrastructure setup will be kept inside your Git repository in your infrastructure. The source code of all used components is public.
We also recommend mirroring all required Docker images. We will setup a Git server and a local container registry if you don’t have one already.
Which hardware can be used?
Any hardware vendors can be used and even mixed in one cluster. It is also possible to use both Intel and AMD CPUs and any GPUs from Nvidia, AMD or Intel. In case you’re looking to purchase new hardware – we are happy to involve our trusted partner for hardware and develop an optimal price/performance setup for your scenario.
Can Cloudification install hardware in our Data Center?
Yes! ✅
Contact us for more details.
Can c12.hpc use other storage solutions instead of Ceph?
Yes! ✅
We have extensive experience integrating and operating NetApp and Pure storage with OpenStack and Kubernetes as well as implementing drivers for vendor storage support in OpenStack.
We also support local RAID storage for both OpenStack and Kubernetes deployments.
Can c12n.hpc be used for SLURM clusters?
Yes! ✅
However, we recommend using containers and Kubernetes wherever possible.
Can c12n.hpc be used for OpenHPC?
Yes! ✅
We can also pre-built VM or container images with desired versions of the software.
Can c12n.hpc installation run fully air-gapped?
Yes! ✅
However, we need remote access for the initial setup.
Is there proactive monitoring and alerting?
Yes! ✅
We can also integrate the c12n monitoring into 3rd party solutions for on-call duty and Slack or other messengers.
In case of support agreements in place, all critical alerts will be worked on within the contractual SLAs.
Is there a logging service available?
Yes! ✅
It is based on OpenSearch project and all logs from all nodes and services in cluster will be collected automatically. This includes audit, kernel, Kubernetes, OpenStack, Ceph and other logs.
Optionally, we can integrate ElasticSearch (ELK stack) upon request.
Turnkey Cloud Solution
End-to-end automated, monitored and secure multi-purpose cloud platform for HPC, AI and ML workloads
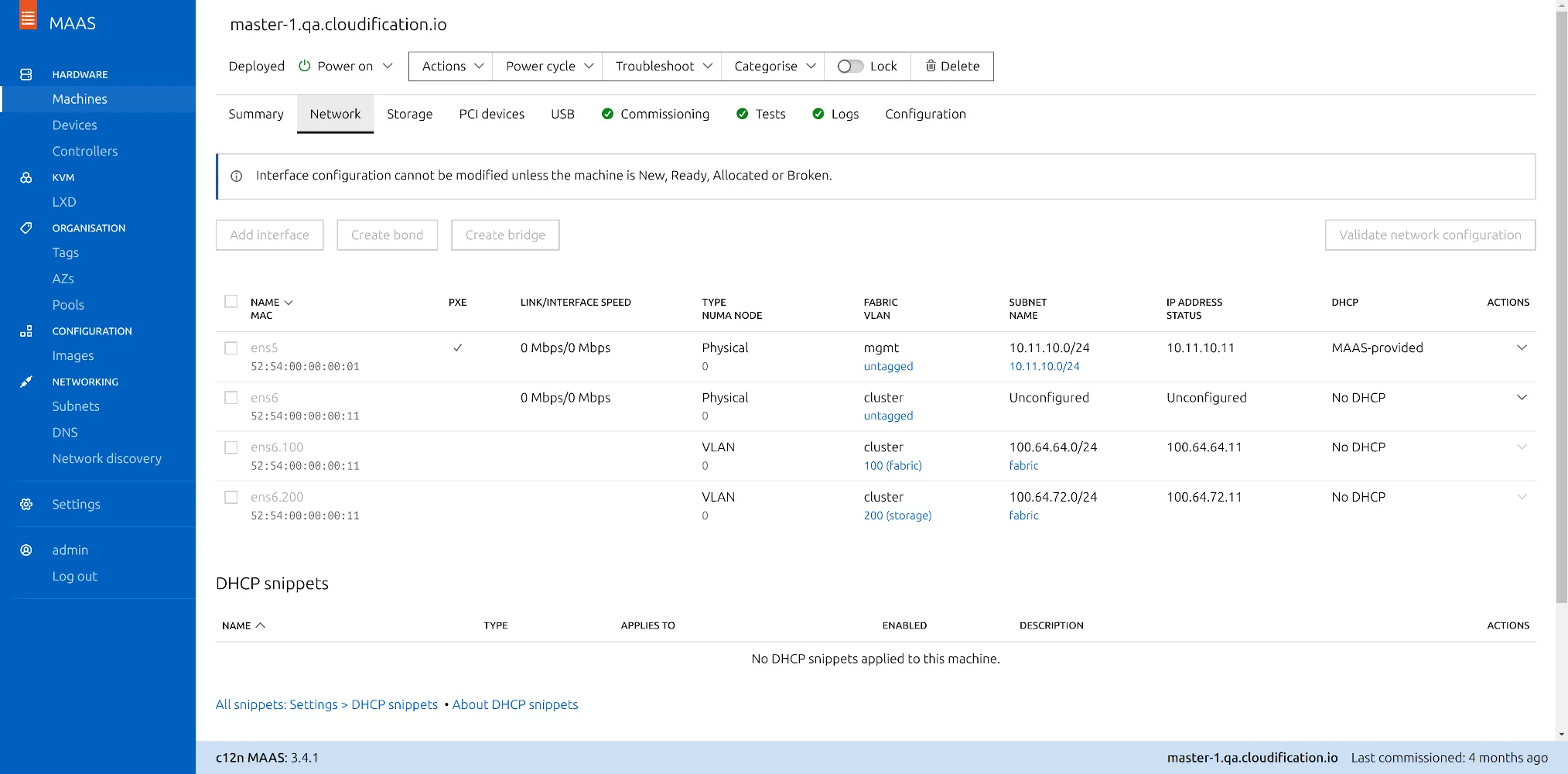
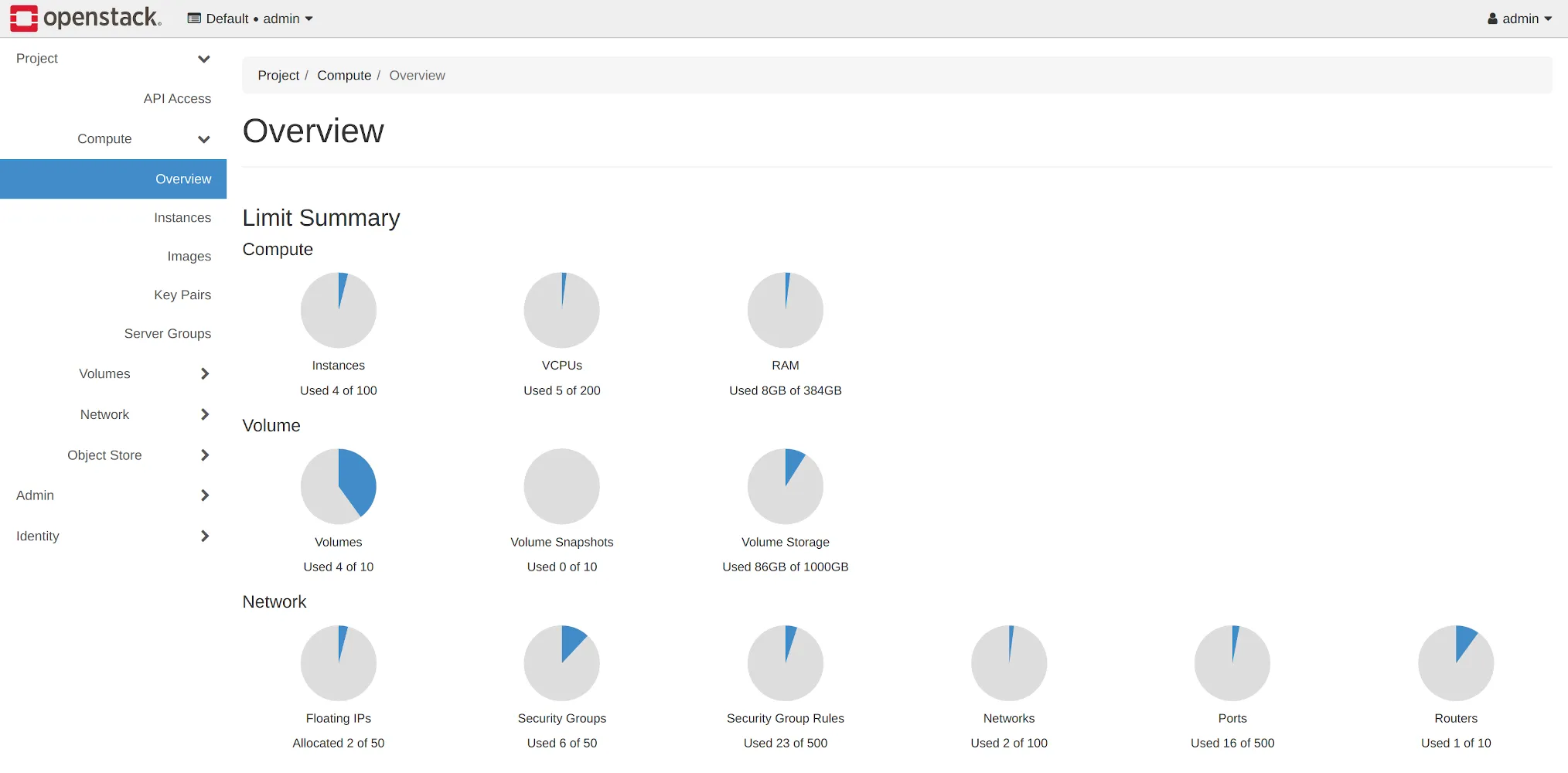
What's new in Cloud?
CHECK OUR BLOG 👇High Performance Cloud computing made easy with c12n.hpc
Experience fully managed, scalable HPC solutions for modern AI, GPU and ML workloads.
