
GitOps Automated OpenStack: Simplifying Release Upgrades and Day-2 Ops
Managing OpenStack can be very complex, especially when dealing with frequent release updates, configuration changes, large scale deployments and tight deadlines. At Cloudification we operate tens of OpenStack deployments of different scales, locations and configurations. To ensure consistency across environments and possible unforeseen complications, an organized approach is needed. Here is where GitOps Automated OpenStack comes in.
For a couple of years now, we’ve implemented GitOps as a powerful framework for automating OpenStack deployments and making updates and day-2 operations smooth and predictable.
In this article you will learn how GitOps can be leveraged to simplify OpenStack release updates and streamline operational workflows and how we take it even further with c12n private cloud solution by integrating GitOps automation into all stages of cloud deployment.
Let’s start by taking a look at OpenStack’s Architecture:
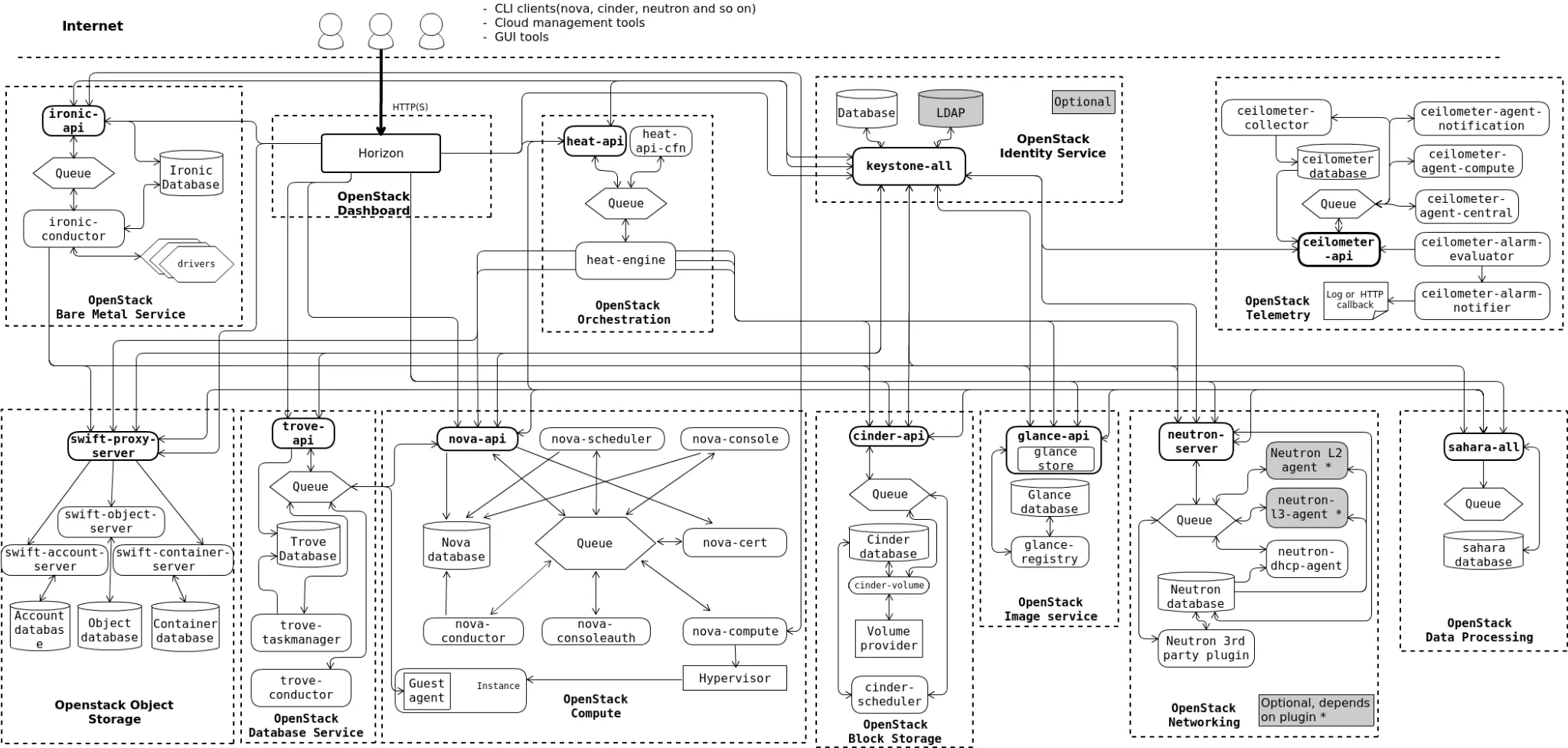
As we have covered in the previous articles, OpenStack consists of multiple core services with a modular architecture that enables additional features. Each service typically has multiple configuration files and multiple components along with dependencies such as databases (MariaDB or similar), message queues (RabbitMQ), caches (Memached) and other service-specific configuration (coordination, policy, etc.)
This can quickly turn into a configuration nightmare, even for experienced administrators. Now multiply that by the number of OpenStack deployments with their specifics and you’d probably end up with the famous meme:

Fortunately, nowadays we have various tools available to simplify OpenStack configuration and deployment, including devstack, openstack-ansible, kolla-ansible, puppet, microstack and Helm charts for Kubernetes. Each tool has its merits but selecting the best one depends on the specific use case and operational requirements
But how do I pick one?
To find out, we first have to talk about containers and why they have become the default way to deploy and manage OpenStack today.
The Role of Containers in OpenStack Deployments
Containers have become the new standard of deploying modern applications, offering great portability and ease of management because they include all application dependencies.
OpenStack container deployment is supported through multiple community-backed approaches amongst which openstack-helm charts is a native choice for organizations operating Kubernetes. Helm charts are packages for Kubernetes clusters that provide a structured way to deploy OpenStack services along with their configurations and dependencies. Those charts are versioned and updated alongside OpenStack releases, ensuring seamless configuration changes and compatibility with the latest versions.
But why introduce Kubernetes as an additional abstraction layer when kolla-ansible can deploy OpenStack containers directly onto control and compute nodes?
Kubernetes has been the buzz word for the past years and today it is the most popular container orchestrator solution that manages the full lifecycle of containers while also offering modularity through plugins that enable different functionality and extend Kubernetes API for special cases. Similar to OpenStack, Kubernetes enables network and workload segmentation, allowing specific roles to be assigned per node (network, storage, control, etc), but does so for containers and not VMs.
Additionally, Kubernetes’ extensibility makes it easy to integrate observability tools (for instance Prometheus, Grafana, Opensearch), additional authentication mechanisms (Keycloak, Dex) and even compliance tools (OPA agents, Trivy, Falco, etc). And all of those can be done using respective Helm charts that can be found in abundance in ArtifactHub.
Automating OpenStack Deployments with GitOps
The Deployment Process
GitOps introduces automation and operational efficiency to OpenStack deployment through two key tools: Git and ArgoCD.
- Git serves as the single source of truth for a complete system configuration, providing visibility, version control, and auditing capabilities.
- ArgoCD continuously monitors and reconciles the desired state of OpenStack components by monitoring Kubernetes objects and maintaining them in the desired state defined in Git.
ArgoCD’s features make it particularly powerful for multi-layered cloud deployments enabling:
- Automated reconciliation of system configuration in case of a ‘drift’ or unexpected manual interventions.
- Dependency management is done via ArgoCD sync waves. Sync waves ensure the correct sequence of service deployments, such as databases and message buses that should be deployed before OpenStack services and the first service deployed should be Keystone as an example.
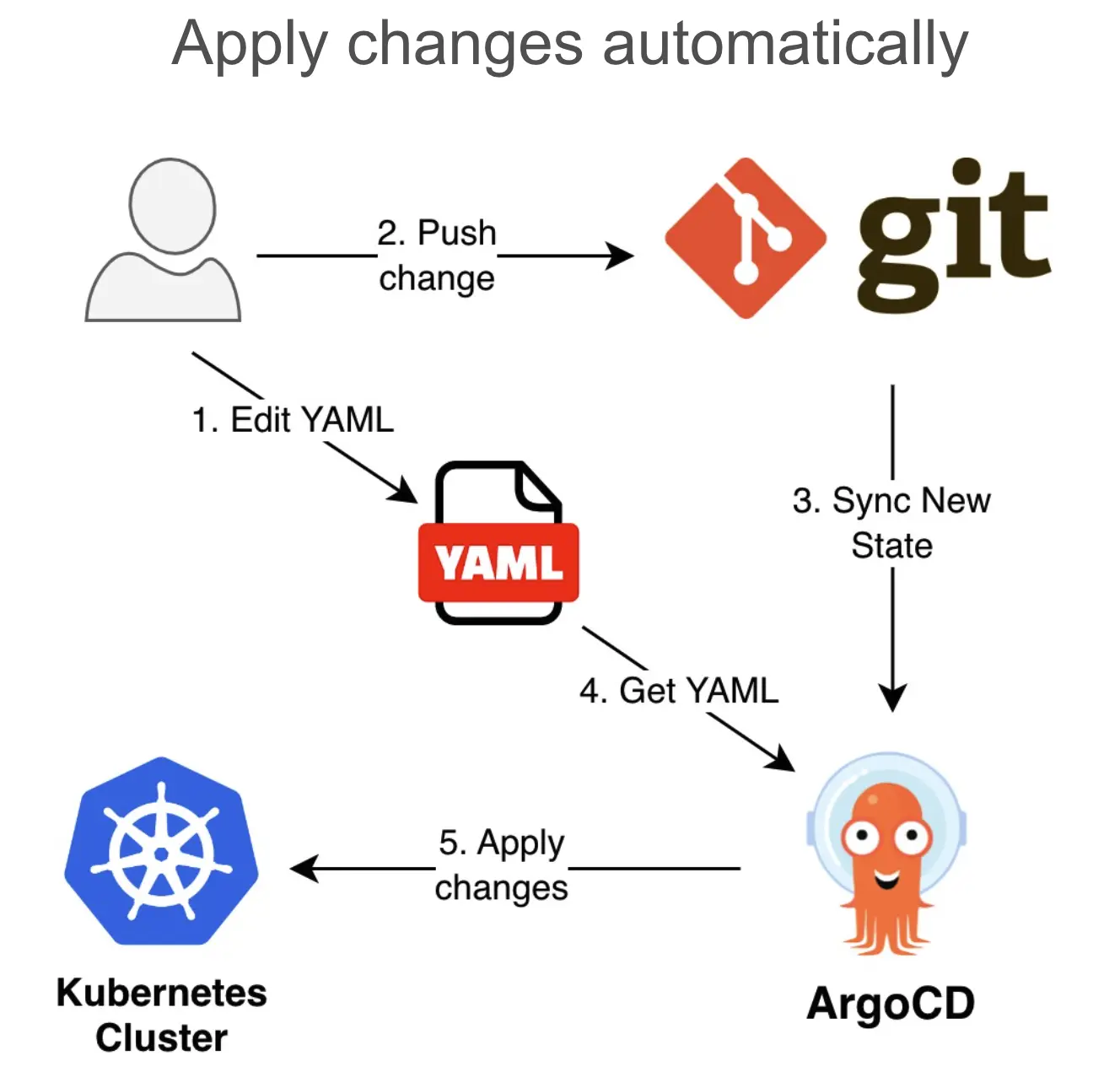
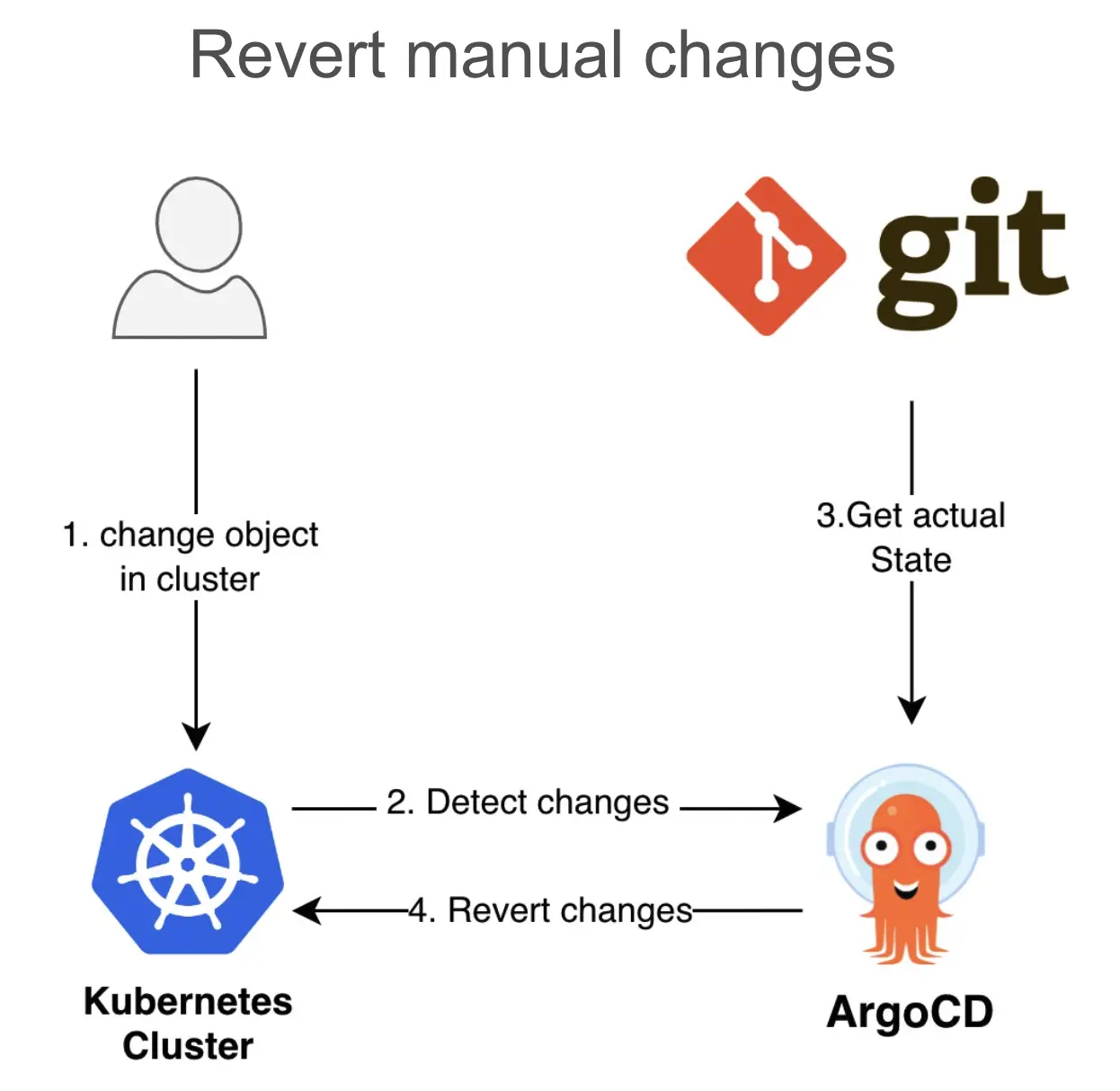
Once the Kubernetes cluster is set up with ArgoCD and apps become green that means the rollout and state synchronization with Git is complete. At this point, adding new cloud nodes of any kind becomes a pretty straightforward process. Install Kubernetes binary (we use official kube-spray SIG), join the node into the cluster and let GitOps automation take care of the rest.
On the screenshots below you can see how OpenStack components, each with their own App look in ArgoCD dashboard:
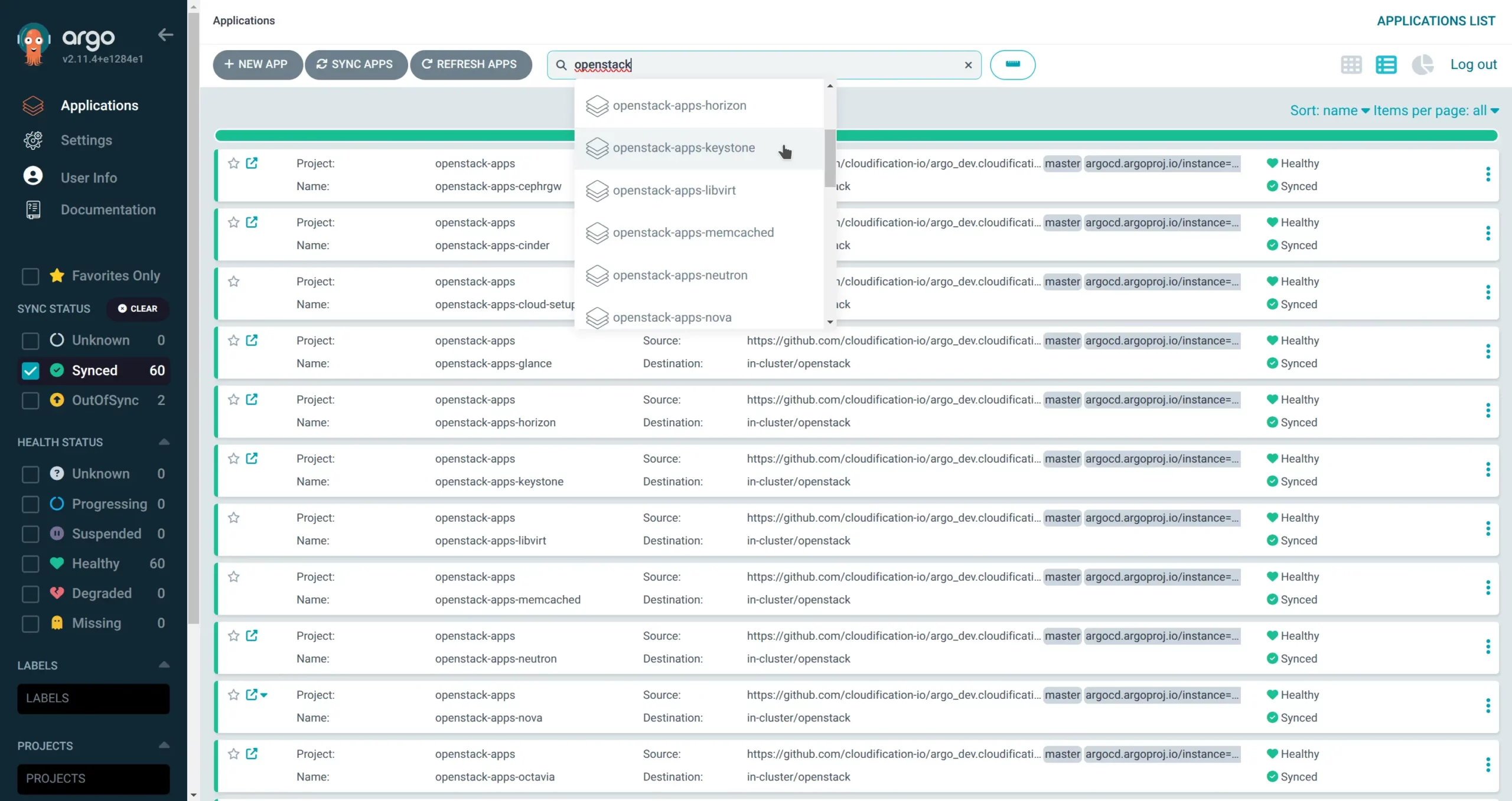
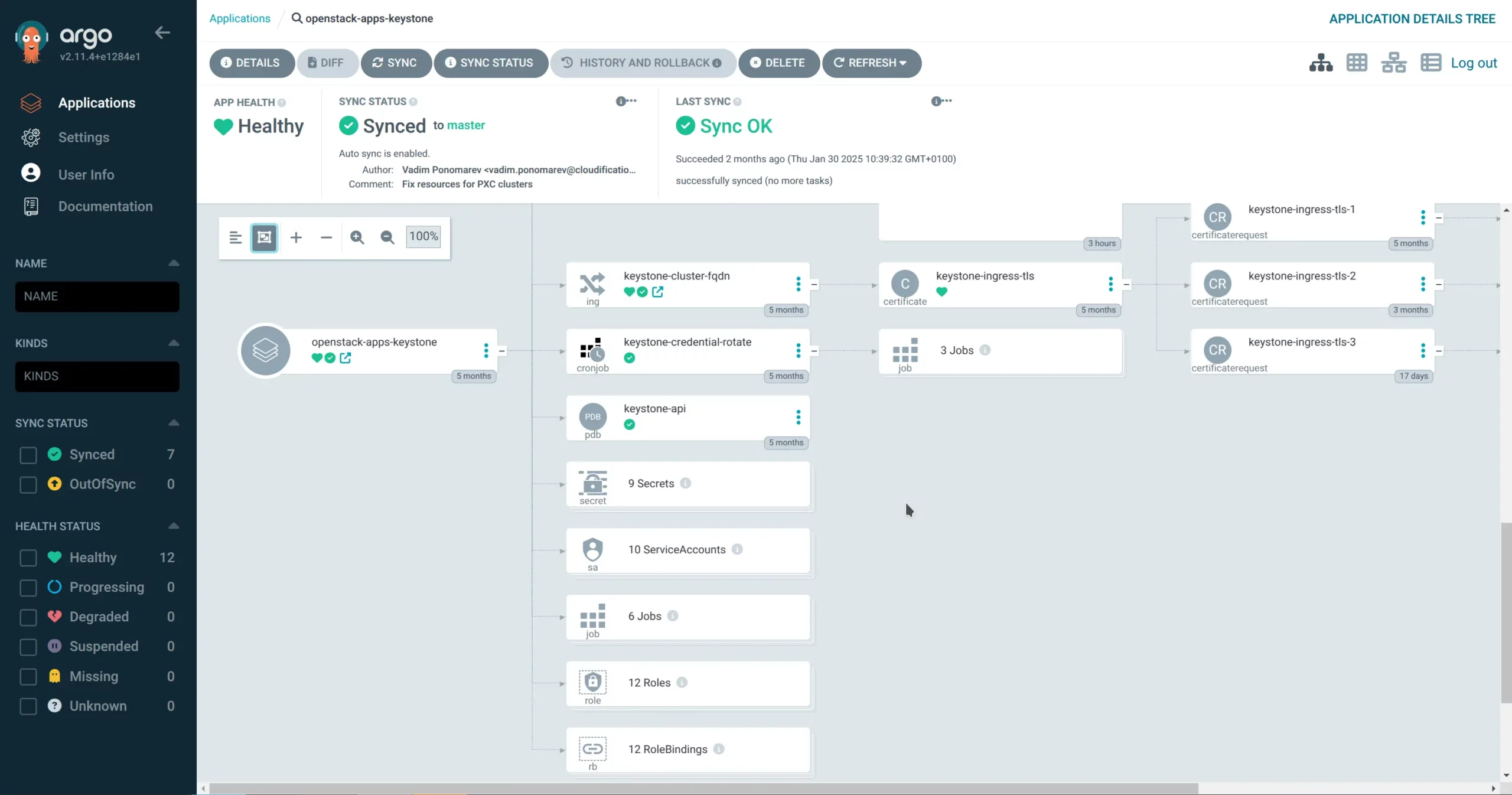
For each Argo App Kubernetes objects (StatefulSets, Deployments, DaemonSets, Services, etc.) will be created and K8s controllers will automatically deploy the necessary OpenStack services based on how the new node is labeled (role label). In our case we use c12n-compute role for compute nodes, c12n-storage-controller for ceph storage nodes and c12n-control-plane for all OpenStack APIs and satellite components (DBs, RabbitMQs, Memcached, etc.):
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master-1.dev.cloudification.io Ready c12n-control-plane,c12n-storage-controller,control-plane,local-storage 139d v1.30.3
master-2.dev.cloudification.io Ready c12n-control-plane,c12n-storage-controller,control-plane,local-storage 139d v1.30.3
master-3.dev.cloudification.io Ready c12n-control-plane,c12n-storage-controller,control-plane,local-storage 139d v1.30.3
worker-1.dev.cloudification.io Ready c12n-compute,local-storage 139d v1.30.3
worker-2.dev.cloudification.io Ready c12n-compute,local-storage 139d v1.30.3
worker-3.dev.cloudification.io Ready c12n-compute,local-storage 139d v1.30.3
And here is how Nova pods in Kubernetes including HA DB and RabbitMQ clusters look like:
# kubectl get pods -n openstack | grep nova
db-nova-haproxy-0 2/2 Running 0 11d
db-nova-haproxy-1 2/2 Running 0 11d
db-nova-haproxy-2 2/2 Running 0 11d
db-nova-pxc-0 4/4 Running 0 11d
db-nova-pxc-1 4/4 Running 0 11d
db-nova-pxc-2 4/4 Running 0 11d
nova-api-metadata-5dbb65685f-dsbwg 1/1 Running 0 11d
nova-api-metadata-5dbb65685f-nrg4j 1/1 Running 0 11d
nova-api-metadata-5dbb65685f-znspr 1/1 Running 0 11d
nova-api-osapi-6cff9f8679-5t5bg 1/1 Running 0 11d
nova-api-osapi-6cff9f8679-bgwv7 1/1 Running 0 11d
nova-api-osapi-6cff9f8679-cljjg 1/1 Running 0 11d
nova-compute-default-9jxp6 2/2 Running 0 11d
nova-compute-default-mpdzp 2/2 Running 0 11d
nova-compute-default-vk62x 2/2 Running 0 11d
nova-conductor-586d8d66d8-nkmpm 1/1 Running 0 11d
nova-novncproxy-58458d5c66-trqfn 1/1 Running 0 11d
nova-novncproxy-58458d5c66-xx2gh 1/1 Running 0 11d
nova-scheduler-584f98bfff-2wpbk 1/1 Running 0 11d
nova-scheduler-584f98bfff-x66cx 1/1 Running 0 11d
rabbitmq-nova-server-0 1/1 Running 0 11d
rabbitmq-nova-server-1 1/1 Running 0 11d
rabbitmq-nova-server-2 1/1 Running 0 11d
Simplifying OpenStack Upgrades with GitOps
How does GitOps make upgrades easier?
OpenStack upgrades have a reputation for being complex, sometimes even painful in the old releases 😅 But situation has improved a lot with the recent OpenStack versions, in fact you only need to upgrade once a year to keep up with the release cycle because every second release comes with SLURP which stands for Skip Level Upgrade Release Process:
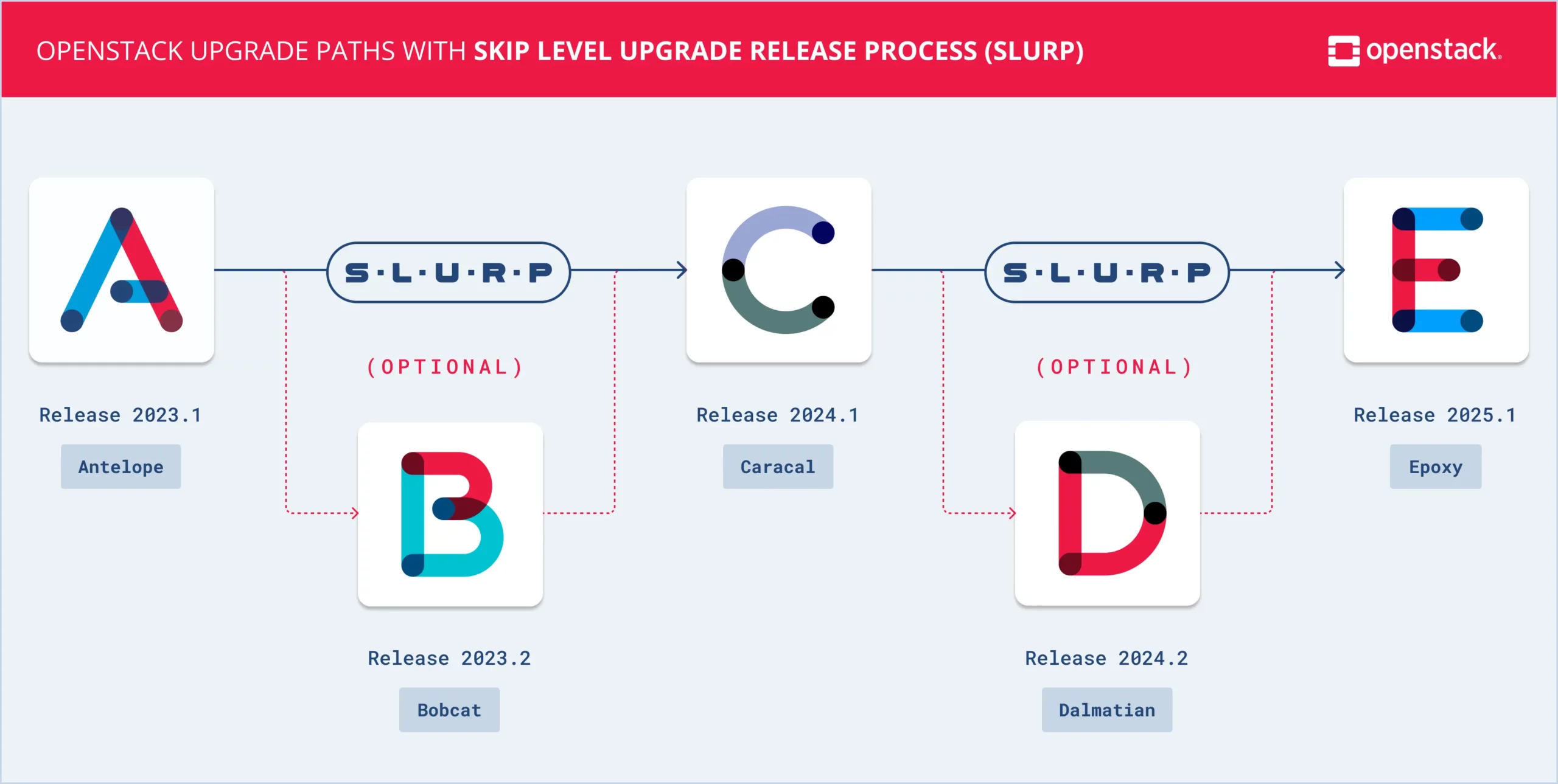
Yet, in our case we want to make our customers’ lifes easier and we do fully GitOps automated release upgrades which run smoothly and fast thanks to:
- Helm Chart Versioning: Helm ensures OpenStack components are upgraded systematically, reflecting the necessary configuration changes.
- Git-based Change Management: Changes to OpenStack configurations are human readable in Git, allowing teams to review the actual diffs before deployment.
- ArgoCD Rollback Capabilities: In case of failure, disabling auto-sync and reverting commits in ArgoCD allows us to roll back to the previous stable state quickly.
Helm, as mentioned earlier, is a package manager for Kubernetes. In the context of OpenStack, openstack-helm charts incorporate all necessary updates to facilitate seamless upgrades between release versions. Once an upgrade is prepared, the differences such as configuration options, image tag changes and others are visible in Git, allowing for verification of changes:
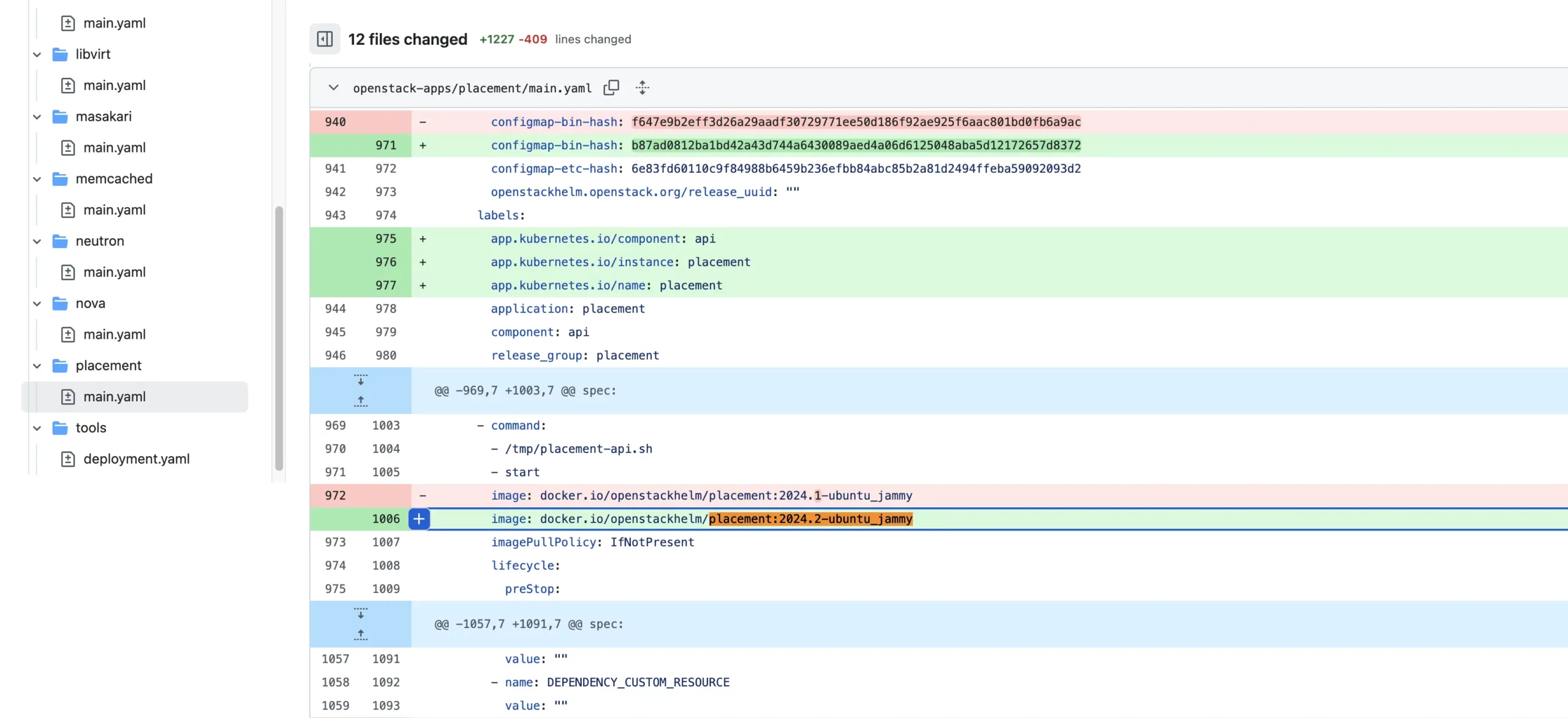
Depending on your approach to upgrades or criticality of the environment you might want to disable auto-sync in ArgoCD and do a controlled App synchronization when the changes have landed into the Git repository. This not only prevents unintended deployments but also enables the rollback feature, allowing a swift return to the previous state in case of failures.
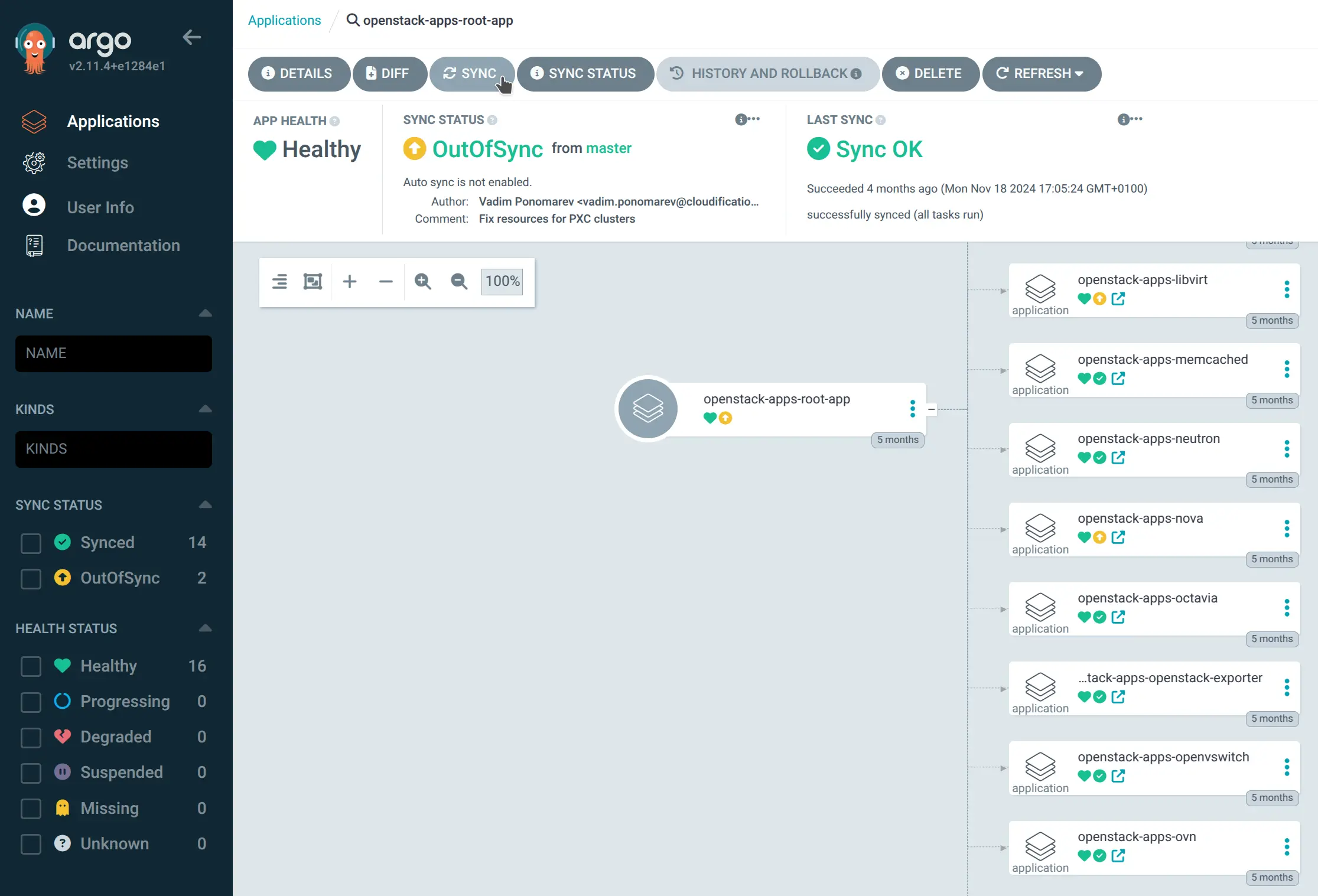
More Reasons to ❤️ GitOps
Beyond automation and ease of upgrades, GitOps provides several key advantages:
- What You See Is What You Get: Ensures that all component configurations are applied correctly, eliminating the need for manual changes and reducing troubleshooting complexity. For example, in case of OpenStack service database schema updates – those will be applied on deployment via Kubernetes Jobs. The service pods started after will wait for migrations to complete before accepting the real requests. The readiness is checked automatically with a so-called readinessProbe from Kubernetes.
- 4-eyes Principle: This principle is nothing new, but still as relevant today as it was years ago. Deployment processes benefit from peer reviews, which improve security and reliability. Deploying to production is always easier when responsibility is shared.
It worked in Dev, Now It’s Ops’ Problem: GitOps ensures consistent environments, bridging the DevOps gap and eliminating configuration and infrastructure drift.

- Automated Security Scanning: In addition to static code analysis, configuration and security audit scans can be performed on Git repositories using cluster-deployed scanners. This helps to implement best practices and identify potential vulnerabilities early.
- Historical Tracking: While thorough testing is crucial for proper system functioning, we all know that not everything can be tested in advance and there is no software that is entirely free of bugs. This is where a well-maintained history of changes becomes invaluable for troubleshooting, allowing teams to track modifications and identify the root cause of issues more efficiently with Git logs and diffs.

Closing Thoughts
We can all agree that GitOps revolutionizes day-2 operations, making deployments more consistent, automated and secure. By combining Git, ArgoCD, Helm and Kubernetes, teams can eliminate much of the complexity involved in managing OpenStack releases, especially at a large scale where traditional tools like Ansible or Puppet show their limits.
By tracking all changes in Git and using ArgoCD for deployments, our OpenStack upgrades became predictable, testable, and even reversible – no more hoping a manual upgrade doesn’t break production.
For organizations looking for a smooth, fully automated and managed OpenStack experience, c12n takes GitOps automation to the next level. In c12n we deploy all payloads including OpenStack, Ceph, Prometheus, OpenSearch and other tools completely via GitOps. If you’re looking to simplify your OpenStack operations with GitOps, we have a team of OpenStack and Kubernetes experts ready to support you.
📨 Get in touch
📚 Browse more topics in our Cloud Blog