
How to Run Scalable AI Inference on Kubernetes and OpenStack Using Gateway API Inference Extensions
The way we build and deploy AI applications has fundamentally shifted. According to the Cloud Native Computing Foundation, a remarkable 66% of organizations now use Kubernetes to host generative AI workloads, yet only 7% deploy these workloads to production daily. This gap represents both a challenge and an opportunity. For platform engineers and cloud architects looking to bridge this divide, the most promising path forward involves mastering AI Inference at Scale on OpenStack — combining the mature infrastructure capabilities of OpenStack with Kubernetes’ powerful new AI-specific networking extensions.
Think of OpenStack as the foundation and plumbing of a smart factory, handling power, cooling, and raw (computing) delivery. Kubernetes acts as the factory’s robotic assembly line, orchestrating individual tasks. The new Kubernetes Gateway API Inference Extensions are the intelligent traffic control system for that factory – directing each AI model request to exactly the right machine at exactly the right time, avoiding traffic jams and idle equipment.
In this article, we’ll explore what these inference extensions are, why traditional routing fails for AI workloads, and how you can implement a production-ready inference platform on OpenStack private cloud.
What Is AI Inference and Why Does It Matter?
Before we dive into technical architecture, let’s take a quick step back to understand the core concept. You’ve probably heard the term “AI inference” thrown around a lot in 2026, but what does it actually mean for your infrastructure?
AI inference is the process of using a trained machine learning model to make a prediction or generate new content based on live input data. Think of it as the “thinking” phase of an AI application. The training phase – where the model learns from massive datasets might happen once a week or once a month, often in a dedicated, high-batch environment. Inference, however, happens in real time, every time a user interacts with your AI enhanced service or product.
When you ask ChatGPT a question, when an autonomous vehicle identifies a pedestrian, or when a fraud detection system flags a transaction — those are all inference requests. Each request must be processed quickly, often in milliseconds, and the infrastructure behind it must handle unpredictable spikes in demand.
The barriers to AI adoption have shifted. Open models like Llama 4, DeepSeek R1, and Qwen 3 now rival proprietary frontier models in quality, and GPU cloud pricing has dropped significantly from $8/hr in 2024 to around $2–3/hr today for high-end devices like Nvidia H100. With capable models and affordable hardware now widely accessible, the bottleneck has moved from building great models to serving them at scale (RunPod, 2026).
This shift has also sparked renewed interest in open infrastructure for AI. In response, the OpenStack community recently published the whitepaper “Open Infrastructure for AI: OpenStack’s Role in the Next Generation Cloud”, co-authored by our CEO. The paper explains how OpenStack’s mature and modular architecture provides a powerful foundation for AI workloads. Services such as Nova and Cyborg enable efficient GPU provisioning, Neutron delivers high-performance networking, and Ironic supports bare-metal deployments – together offering a scalable, production-ready platform for AI inference without vendor lock-in. But having the right infrastructure foundation is only part of the equation.
Here’s the challenge in a nutshell: Unlike traditional web applications where each request is roughly equal (e.g., loading a webpage), inference requests are wildly uneven. A request that asks for a one‑sentence answer might consume 100 tokens of compute, while a request asking for a detailed analysis could consume 10,000 tokens – a 100x difference in cost and compute time. Traditional load balancers that just round‑robin requests will inevitably create “hot spots” on some GPUs while others sit idle, wasting expensive resources and frustrating users with slow responses.
This is why specialized infrastructure matters. By mastering AI Inference at Scale, you gain the ability to serve hundreds or thousands of requests per second across a shared pool of GPUs, with intelligent routing that adapts to real‑time GPU memory usage, request queue depths, and even the specific models or LoRA adapters that are already loaded. The result is lower latency, higher throughput, and dramatically lower costs.
Why Traditional K8s Ingress Fails for AI Inference
Now that we understand what inference is, let’s look at why standard Kubernetes Ingress controllers break under its weight. Traditional Kubernetes Ingress controllers were designed for stateless web applications. A typical HTTP request might take 50 milliseconds and consume relatively uniform resources. AI inference is radically different.
When you send a request to a Large Language Model (LLM) like Llama 3.3 or DeepSeek R1, the workload is unpredictable. The inference process has two distinct phases: prefill (encoding your input) and decoding (generating each token of the response).
Here’s what breaks with traditional Ingress and load balancing:
| Challenge | Why It Fails with Standard Ingress | How K8s Inference Extension Solve It |
|---|---|---|
|
Variable request costs |
Round-robin distribution assumes equal cost of request, leading to GPU hot spots and unbalanced utilization |
Routes based on real-time GPU cache utilization and queue length |
|
Model-specific routing |
Can only route by URL path or hostname |
Routes intelligently by model name from the OpenAI API spec |
|
Token-aware rate limiting |
Limits by request count, not compute weight |
Limits by token count — a single 10k token request counts appropriately |
|
GPU memory fragmentation |
No visibility into KV cache usage |
Prefers backends with higher available GPU cache for faster processing |
The Kubernetes community recognized these gaps and, through the Gateway API working group, developed the Inference Extension specification. First announced at KubeCon EU 2025 (and maturing throughout 2026), this extension has quickly gained adoption from major vendors including Solo.io, NVIDIA, and Alibaba Cloud.

Understanding the Gateway API Inference Extension
The Inference Extension introduces two new custom resource definitions (CRDs) that work alongside the standard Gateway API:
InferencePool
An InferencePool represents a group of pods that share the same compute configuration, accelerator type, base model, and model server (like vLLM). Think of it as a “pool” of GPU workers all capable of serving the same model family. A single InferencePool can span multiple Kubernetes nodes and even multiple VMs or availability zones, providing high availability. Here’s what the configuration looks like (simplified for readability):
apiVersion: inference.networking.k8s.io/v1alpha1
kind: InferencePool
metadata:
name: llama4-pool
spec:
selector:
matchLabels:
app: llm-inference
model: llama4-17b
minReplicas: 3
maxReplicas: 10
targetLoad:
gpuCacheUtilization: 75 # Scale when cache usage exceeds 75%InferenceModel
An InferenceModel declares which model names are served by pods within an InferencePool. It also defines service properties like criticality level. Critical workloads (such as real‑time user requests) receive priority scheduling when GPU resources are contested, while best‑effort batch jobs can be shed first.
apiVersion: inference.networking.k8s.io/v1alpha1
kind: InferenceModel
metadata:
name: llama4-critical
spec:
poolRef:
name: llama4-pool
modelName: llama4-17b-instruct
criticality: Critical # Gets priority over BestEffort workloadsHow Smart Routing Works
When a request arrives, Kubernetes Gateway with Inference Extension doesn’t just look at the URL. It inspects the request body (following the OpenAI API format) to identify which model is being requested. It then evaluates real-time metrics from each backend pod, including:
- Queue length — how many requests are already waiting
- GPU cache utilization — how much of the KV cache is occupied
The gateway then routes the request to the pod with the shortest queue and most available cache. This intelligent routing dramatically reduces Time to First Token (TTFT) — the user-perceived latency that makes an AI application feel responsive or sluggish. For example, in tests using the Inference Extension with Envoy Gateway, critical requests are routed to pods with queues under 50 and low cache usage, while non‑critical traffic can be shed if all backends reach 80% or higher cache utilization (Kgateway, 2025). Schematically, this is how it looks:
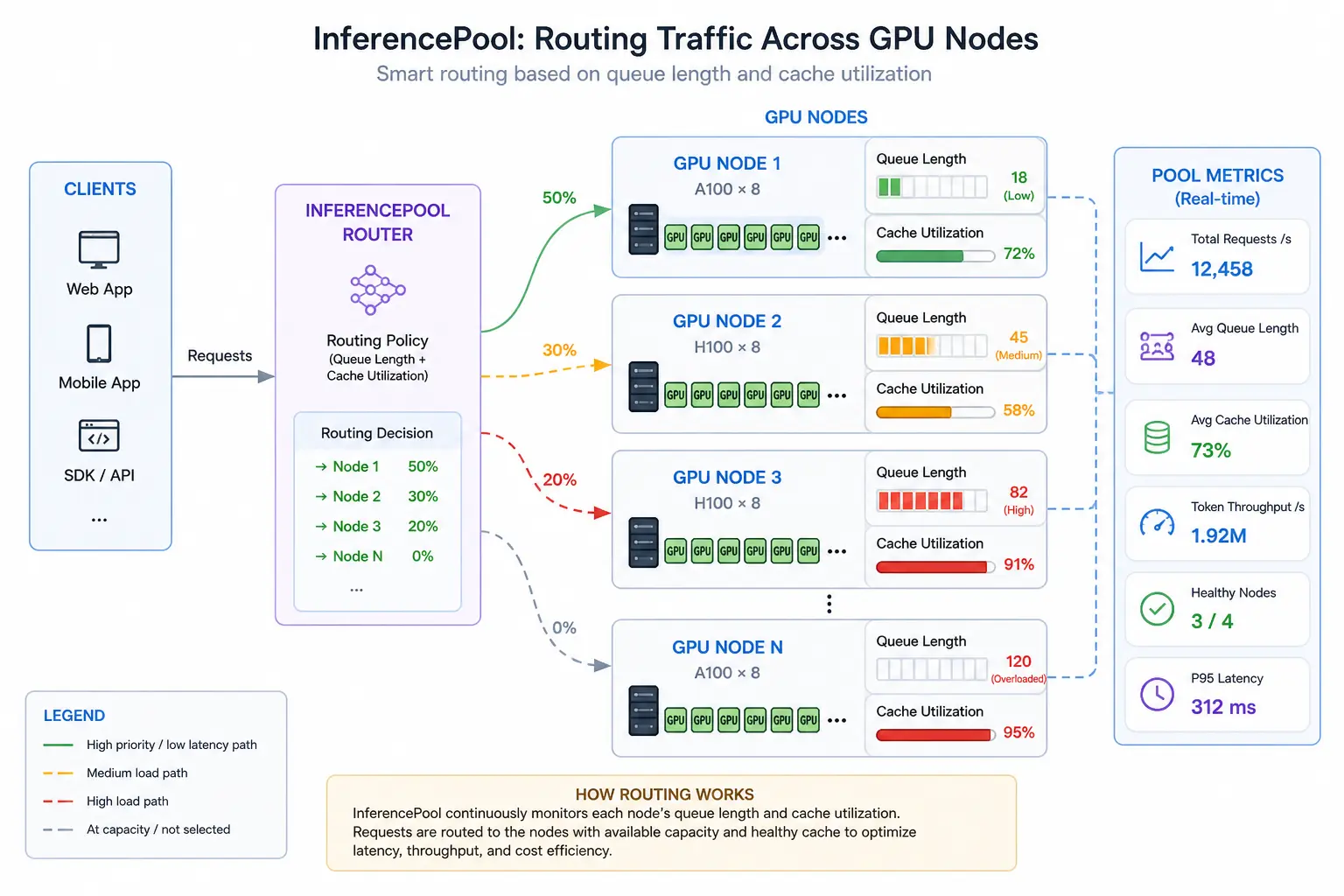
Building the Inference Platform with OpenStack & Kubernetes
Now that we’ve covered the Kubernetes part, the question still remains where and how to run those K8s clusters with Inference extension? These clusters need a robust underlying infrastructure and running those in the public cloud with GPUs at a scale will quickly cost a fortune. This is where private cloud and OpenStack will deliver lower TCO over time and pay off for the initial hardware investment.
OpenStack provides three critical capabilities for AI inference at scale:
1. Flexible GPU Resource Management
Not all inference workloads are created equal. Some need dedicated GPU performance. Others can share GPUs. OpenStack gives you three options:
- PCI Passthrough: For production inference requiring maximum throughput. The VM gets direct, exclusive access to a physical GPU and near-bare-metal performance. While easy and fast to set up, VMs with PCI passthrough are not supported by live-migration, making infra maintenance a bit more difficult.
- vGPU (Virtual GPU): A single GPU is shared across multiple VMs, optimizing hardware utilization and allowing to share a single GPU on multiple VMs (and Pods) which is handy for development and testing.
- MIG (Multi-Instance GPU): For multi-tenant environments on MIG-capable GPUs (such as Nvidia A100, H100, H200 and others). The GPU is hardware-partitioned into fully isolated instances with guaranteed memory and compute resources. Up to 7 partitions can be created on a single GPU.
With our own c12n private cloud, we support all three options allowing great flexibility when it comes to building an AI ready cloud with Kubernetes clusters running on VMs provisioned with Gardener.
2. High-Performance Storage for Model Weights
Large language models are, well, large as the name implies. Llama 4 Maverick (17B active parameters) requires significant storage, and full MoE models like DeepSeek R1 (671B total parameters) are even larger. c12n uses Ceph via the Rook operator to provide three storage interfaces from a single cluster:
- Block storage (RBD) via Cinder for any VM-attached volumes (root or secondary)
- Object storage (S3) via RADOS Gateway for model artifacts or generic data
- Shared file storage (NFS/CephFS) for multi-user access
While Ceph is perfectly capable of delivering millions of IOPS, it is not the most performant storage solution out there. In fact, nothing really beats NVMe local storage directly attached from the hypervisor where the VM is running, providing lowest possible latency and highest IOPS. This is not a solution for all scenarios, though.
Real-World Performance Potential
While every deployment is unique, organizations moving from public cloud to optimized on-premises OpenStack + Kubernetes platforms often see certain improvements. Based on patterns observed across the industry, these benefits typically include:
- Lower and more consistent latency – By eliminating network variability and adding GPU‑aware routing, Time to First Token (TTFT) can be reduced by 50%.
- Dramatically lower per‑token costs – accounting for typical 3-5 year hardware amortization, on‑prem inference costs 60-80% less than equivalent public API usage. And initially high upfront costs can be avoided if the hardware is leased.
- Full data sovereignty – For regulated industries (finance, healthcare, government), keeping inference on‑prem eliminates data residency concerns.
The exact numbers depend a lot on your model sizes, request patterns, and hardware choices. What matters is that the architecture we’ve described — OpenStack + Kubernetes + Gateway API Inference Extensions — makes these improvements realistically achievable.
What’s Coming Next?
The Kubernetes AI ecosystem is evolving rapidly. Based on announcements from KubeCon EU 2026 and the CNCF landscape, here’s what to watch:
llm-d for Distributed Inference
IBM, Red Hat, and Google Cloud donated llm-d to the CNCF. This project splits inference workloads by separating prefill and decode phases across different pods, reducing latency by 40‑60% for large models.
Nvidia DRA Driver for Fractional GPU Allocation
NVIDIA donated its Dynamic Resource Allocation driver to the CNCF, enabling fine‑grained GPU sharing — imagine using 0.3 of a GPU for one workload and 0.7 for another with hardware‑level isolation.
Getting Started with c12n Private Cloud
You don’t need to build this infrastructure from scratch. c12n private cloud provides a production-ready foundation that includes:
- ✅ OpenStack with GPU passthrough, vGPU, and MIG support
- ✅ Kubernetes clusters provided via Gardener on OpenStack
- ✅ Ceph or local cloud storage
- ✅ GitOps automation with ArgoCD
- ✅ 24/7 human support
Ready to take control of your AI infrastructure?
Contact us to schedule a technical assessment with our team. We’ll help you design a sovereign, cost-predictable AI inference platform that puts you back in control of your data and your budget.