
Discover The Power of Event Streaming with Kafka
In today’s digital landscapes, processing and responding to data in real-time has become a common requirement. Apache Kafka is one of the most popular solutions today in the world of event streaming. But what is Kafka exactly? And how can it benefit businesses?
First things first, what is event streaming?
Event Streaming is the practice of capturing, processing, storing, and transmitting a series of events (data points that represent state changes) in real-time or near-real-time. These events can be generated by a multitude of sources, such as user activities on a website, sensor readings in IoT devices, or transactions in financial systems.
It ensures a continuous flow and interpretation of data so that the right information is at the right place, at the right time.
Event streaming is very versatile and can be used in a variety of scenarios. Let’s take a look at a few examples:
- Real-time Analytics: for analyzing and responding to data in real-time, such as fraud detection in financial systems or monitoring user engagement in apps.
- Data Integration: event streams can integrate data from multiple sources, allowing decoupled systems to communicate and share data efficiently.
- System Monitoring: monitoring system health, performance metrics, and logging information in real-time.
- IoT (Internet of Things): streaming data from sensors and devices for monitoring, analytics, and control purposes.
- Online Retail: for tracking user behavior, inventory changes, or real-time recommendations.
- Microservices Architecture: allows microservices to communicate and react to events from other parts of the system.
What is Kafka?
Kafka is an open-source distributed event streaming platform that was originally developed at LinkedIn and was later donated to the Apache Software Foundation.
Kafka allows for the development of real-time event-driven applications, meaning it is designed to handle real-time data feeds with high throughput and fault tolerance, making it a go-to choice for large scale event streaming applications.
More specifically, it allows developers to make applications that continuously produce and consume streams of data records. It is used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Users of modern day applications expect a real time experience and Kafka often becomes an answer to the problems faced by the distribution and the scaling of messaging systems.
Kafka Architecture
Now let’s take a brief look at Apache Kafka is designed as a distributed system that operates in real-time. It is scalable and allows data streams to be partitioned and spread across a set of machines without manual intervention.
This is achieved through a combination of its main components: Producers, Brokers, Topics, Partitions, and Consumers. These are illustrated in the diagram below:
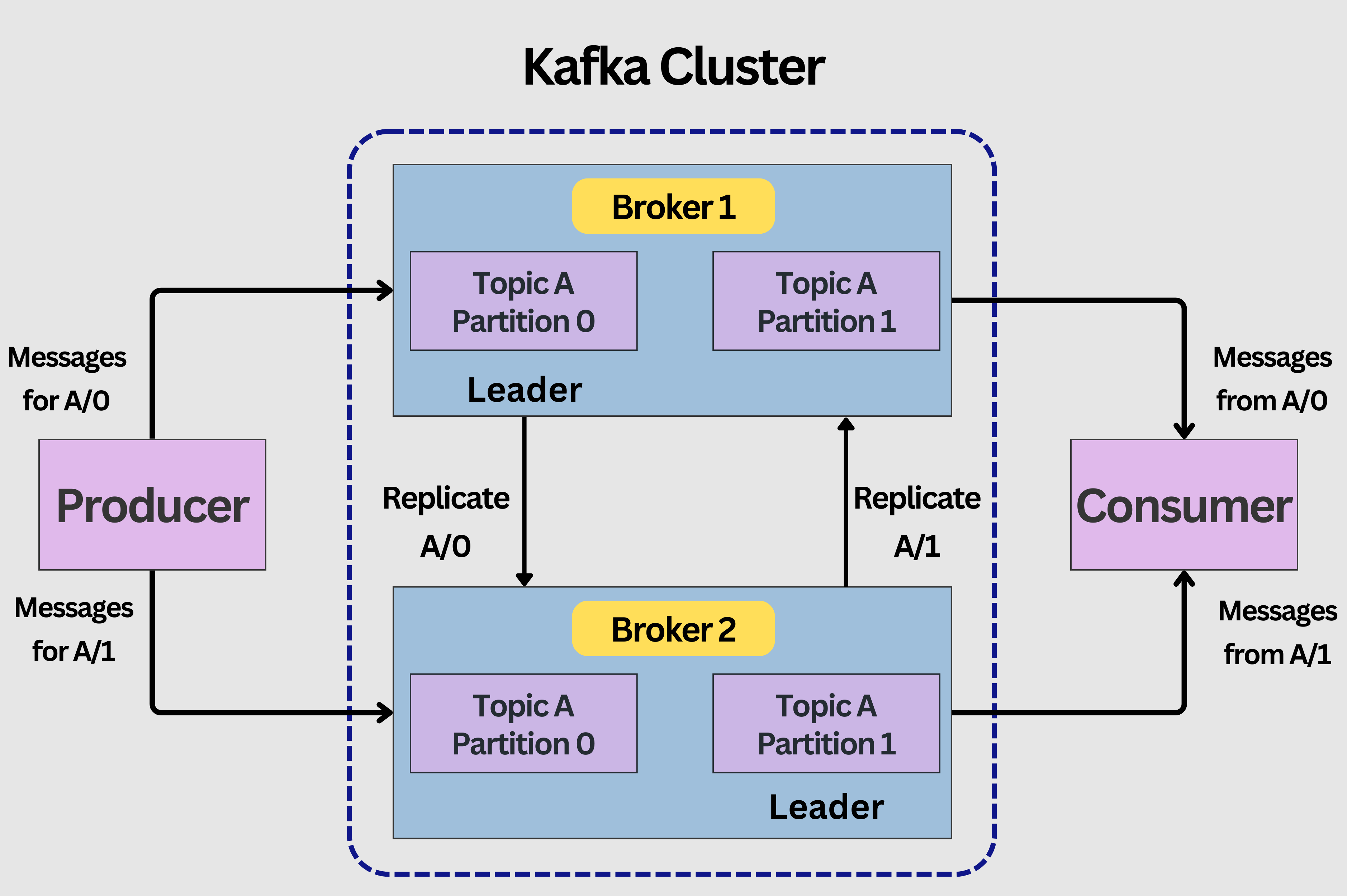
Brokers: Kafka servers that store data and cater to clients and it is the core component of Kafka messaging system. A Kafka cluster usually consists of multiple brokers in order to maintain load balance.
One Kafka Broker instance can handle hundreds of thousands of reads and writes per second. However, Kafka ZooKeeper is needed to maintain the cluster state since the brokers are stateless.
ZooKeeper: This is an additional component for managing and coordinating Kafka brokers. It notifies producer and consumer about the presence of any new broker in the Kafka system or failure of the broker in the Kafka system. When the Zookeeper informs about the presence or failure of the broker, the producer and consumer takes action and starts coordinating their task with some other broker.
Producers: They publish messages to one or more topics. Producers send data to the Kafka cluster. When a Kafka producer publishes a message to Kafka, the broker receives the message and appends it to a particular partition. Producers are given a choice to publish messages to a partition of their choice.
Consumers: They read data from the Kafka cluster that has been pulled from the broker when the consumer is ready to receive the message. A consumer group consists of many consumers that pull data from the same topic or same set of topics.
Topics: These are categories under which messages or events are published. In Kafka, data is stored in the form of topics. Producers write their data to topics, and consumers read the data from these topics.
Partitions: Topics can be split into these, allowing data redundancy and parallel processing. Partitions are separated in order. The partitions comprising a topic are distributed across servers in the Kafka cluster.
Events: An event records the fact that “something has happened” in the world, in your business, device or an application. When you read or write data to Kafka, you do this in the form of events.
How does Kafka work?
Kafka operates as a distributed system, which means it runs on multiple nodes. At its core, Kafka works by receiving events from producers, storing these events in a fault-tolerant manner, and allowing consumers to read events at their own pace.
There are three main capabilities that allow users to implement use cases for event streaming end-to-end with Kafka:
- Publishing: It enables applications to publish (write) and subscribe to (read) event streams, including continuous import/export of your data to or from other systems.
- Storing: It stores streams of events durably and reliably (i.e., in the order in which they occurred), and it does so in a fault-tolerant and durable way. The replication factor is configurable.
- Processing: It processes streams of events as they occur or retrospectively.
The above-mentioned capabilities can be leveraged by developers through five core APIs that make Kafka versatile and allow developers and businesses to build a wide variety of real-time data streaming applications from a simple data pipeline to a complex stream processing system. Let’s take a look at them:
- Producer API:
Purpose: This API allows applications to send streams of data to topics in the Kafka cluster. A topic is a named log that stores the records in the order they occurred relative to one another. After a record is written to a topic, it can’t be altered or deleted. Instead, it remains in the topic for a preconfigured amount of time – for example, for an hour, two days – or until storage space runs out.
Features: Provides mechanisms to control data acknowledgment, partitioning data across multiple brokers, and handling failed sends. - Consumer API:
Purpose: Allows applications to read streams of data from topics in the Kafka cluster, subscribe to one or more topics and process the stream stored in the topic.
Features: Allows for the consumption of data from one or more topics, provides mechanisms for both manual and automatic offset management (e.g. where the reading starts), and can facilitate processing the same data in multiple consumers via consumer groups. - Streams API:
Purpose: Used for building stream processing applications, it allows transforming streams of data from input topics to output topics. While the Producer and Consumer APIs can be used for simple stream processing, the Streams API enables development of more sophisticated data- and event-streaming applications.
Features: Enables processing of data in real-time, stateful and stateless operations, windowing support, and building lightweight applications that can both consume and produce data. - Connect API:
Purpose: Helps in building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems (such as databases).
Features: Enables integration of Kafka with other systems without writing much code, supports both source connectors (sending data to Kafka) and sink connectors (reading data from Kafka). - The Admin API:
Purpose: Provides administrative capabilities to manage and inspect topics, brokers, and other Kafka objects.
Features: Creation, deletion, and inspection of topics, managing configurations, and querying the status of the cluster.
Kafka’s Capabilities
Kafka has many capabilities that have been designed keeping in mind the challenges and requirements of modern data-driven applications, let’s take a look at some of them:
High Throughput: Kafka can handle millions of messages per second, allowing businesses to process massive amounts of data in real-time.
Fault Tolerance: Even if a few nodes fail, Kafka remains operational, ensuring continuous data streaming.
Real-time Processing: Kafka can be used with real-time analytics platforms, enabling businesses to make decisions on-the-fly.
Distributed Data Streaming: Kafka operates as a distributed system where data is split over partitions. These partitions are spread across multiple nodes ensuring data availability and parallel processing.
Aside from rich capabilities, Kafka integrates well with many databases, frameworks, and platforms, such as Apache Spark, Apache Storm and Apache Hadoop using Kafka Connect and Kafka Streams tools.
Who is using Kafka?
Kafka has become an integral component in the architectures of many popular services and platforms across various domains due to its ability to handle real-time data streams efficiently. Here are a few well-known companies where Kafka plays a critical role in their systems:
LinkedIn:
Kafka was originally developed at LinkedIn to handle its growing need for real-time analytics and monitoring. It’s used for tracking user activity, monitoring system health, and driving various real-time features on the platform. Kafka has allowed LinkedIn to process billions of events every day, leading to more real-time insights and improved user experiences.
Netflix:
Netflix utilizes Kafka for real-time monitoring, event processing and orchestration ensuring the seamless streaming of movies and series to millions of users worldwide. Kafka has contributed to enhancing the reliability of streams, improving anomaly detection, and more efficient data processing, contributing to a smooth user experience.
Uber:
Uber uses Kafka for tracking every aspect of its operations in real-time, from driver locations to transaction logs. It’s a key component in their microservices-based architecture, providing real-time data that aids in optimizing ride allocation, pricing decisions, and ensuring timely rides for users.
Spotify:
Spotify, a music streaming giant, uses Kafka for tracking user activities, building real-time analytics and recommendations, and for the integration of various services in its backend.
It helps in delivering personalized music experiences to users by analyzing real-time listening patterns.
In all these cases, Kafka’s ability to handle huge amounts of real-time data reliably and at scale has been playing a key role. Its features enable some of the largest tech companies in the world to derive insights quickly, ensure seamless operations, and deliver better experiences to end-users.
Pros and Cons
As with any technology, it’s essential to go beyond its popularity and hype and evaluate its core capabilities, strengths, and areas of improvement. Understanding a system’s limitations is crucial at the stage of design. Let’s take a look at some of the advantages and a few setbacks.
Advantages
Resilience: Built-in fault tolerance due to its distributed nature.
Flexibility: Can connect to various data sources and sinks.
Ecosystem: A rich array of tools, extensions, and integrations.
Community Support: Vibrant community and extensive documentation.
Scalability: scale up by adding more brokers without downtime.
Durability: events are replicated across multiple nodes in Kafka cluster and remain accessible after a consumer reads them.
Disadvantages
Complexity: Due to its advanced features, the learning curve can be quite steep.
Operational Overhead: Running and managing a Kafka cluster requires operational expertise and following best-practices.
Dependency on ZooKeeper: Although plans are underway to remove this dependency for coordination, currently, ZooKeeper is still essential for managing Kafka clusters.
Conclusion
Kafka’s massive rise in popularity over the last few years is not coincidental. Its capabilities and design cater to the needs of modern businesses and developers navigating complex data-driven distributed architectures.
Kafka capabilities ensure that data flows are maintained with high resilience, scalability, and throughput — all essential elements for present-day applications that demand real-time processing and analysis. Although its inherent complexity can pose challenges, the potential rewards in terms of data processing efficiency are unmatched.
All in all, Kafka is a prime candidate for organizations aiming to keep pace with the ever-evolving landscape of data management and stream processing.
Want to harness the power of Apache Kafka for your business? Contact us today and schedule a call.