
Understanding OpenStack Nova Cells: Scaling Compute Across Data Centers
As cloud infrastructure grows in size and complexity, managing compute resources efficiently becomes crucial – not just for performance, but for high availability, fault tolerance, and long-term scalability. If you’re running OpenStack and planning to expand beyond a single data center or scale to hundreds of hypervisors, OpenStack Nova Cells should be on your radar.
In this article, we explore what Nova Cells are, when and why to use them, and how they can help you manage a geographically distributed or large-scale OpenStack deployment.
Keeping up with this fast-paced evolution is far from easy. The good news is that we at Cloudification have spent years building and operating OpenStack environments – from lean developer testbeds to production cloud infrastructures with tens of thousands of instances. Our expertise has led us to create our own c12n Private Cloud Solution, which delivers enterprise-grade OpenStack and now we want to share some of that knowledge with you by creating a compilation of the Best Practices that we have learned along our OpenStack journey.
We’ve prepared this guide for you to help you get the most out of your OpenStack deployment, whether you’re just getting started or scaling up to support demanding mission-critical workloads. This guide consolidates cloud architecture design and operational best practices. Some of these choices – especially related to storage, networking, and service layout – should be considered early in the design process, as they can be difficult, if not impossible, to change later.
P.S. If you’re new to our blog – or just beginning your OpenStack journey and want to get up to speed—we invite you to check out our earlier OpenStack articles where we cover the basics (and a little bit more). It’s a great place to start before diving into the deeper best practices we explore here.🤿
What Are OpenStack Nova Cells?
Nova Cells are a core architectural component of the OpenStack Nova service that allow you to scale compute resources horizontally while maintaining a unified control plane. Each Nova Cell is a logically isolated compute domain with its own database, message queue, scheduler, and compute nodes.
At the top of the architecture is the Nova API layer, which communicates with all the underlying cells, providing a consistent experience for users and other OpenStack components. There’s also a special system cell called cell0, used to house instance records that fail during scheduling.
This cell-based architecture is critical for large-scale and distributed OpenStack deployments.
Why Nova Cells Matter
Without Nova Cells, all compute resources are managed under a single control plane. That’s fine for small and mid-sized environments – but when you’re dealing with hundreds of nodes or multiple data centers, that approach can lead to database contention, slow scheduling, and complex failure scenarios.
Here’s how Nova Cells make a difference for larger OpenStack deployments.
Scalability
Cells allow you to scale your Nova control plane horizontally. Each cell operates independently, which avoids overloading a single database or message queue and helps maintain performance as your cloud grows.
Fault Isolation
Because each cell is autonomous, a failure in one cell doesn’t take down the others. This isolation simplifies operations and increases resiliency.
Geographical Distribution
You can place different cells in different availability zones or data centers. This is especially useful when each location has its own power, cooling, or internet provider. With cells, you can treat multiple physical sites as one logical cloud. It also does not have to be actual data centers – could be floors or rooms in one DC.
Centralized API, Decentralized Infrastructure
Despite the distributed backend, your users interact with a single, unified OpenStack Nova API. That means developers and operators can launch and manage workloads across all cells seamlessly without caring how it works in the background.
Example: Multi-Datacenter Cloud with Redundancy
Suppose you have two data centers side-by-side. Each has its own network provider, physical infrastructure, and compute capacity. You want to avoid a single point of failure while providing seamless service.
By defining each data center as a Nova cell:
- You gain redundancy and fault isolation
- Users can choose availability zones and spread their workloads for better fault tolerance
- If one cell becomes unreachable, others remain operational
- You maintain a single API and control plane, but it is recommended to spread the main Nova DB, RabbitMQ and API across both DCs in such scenario
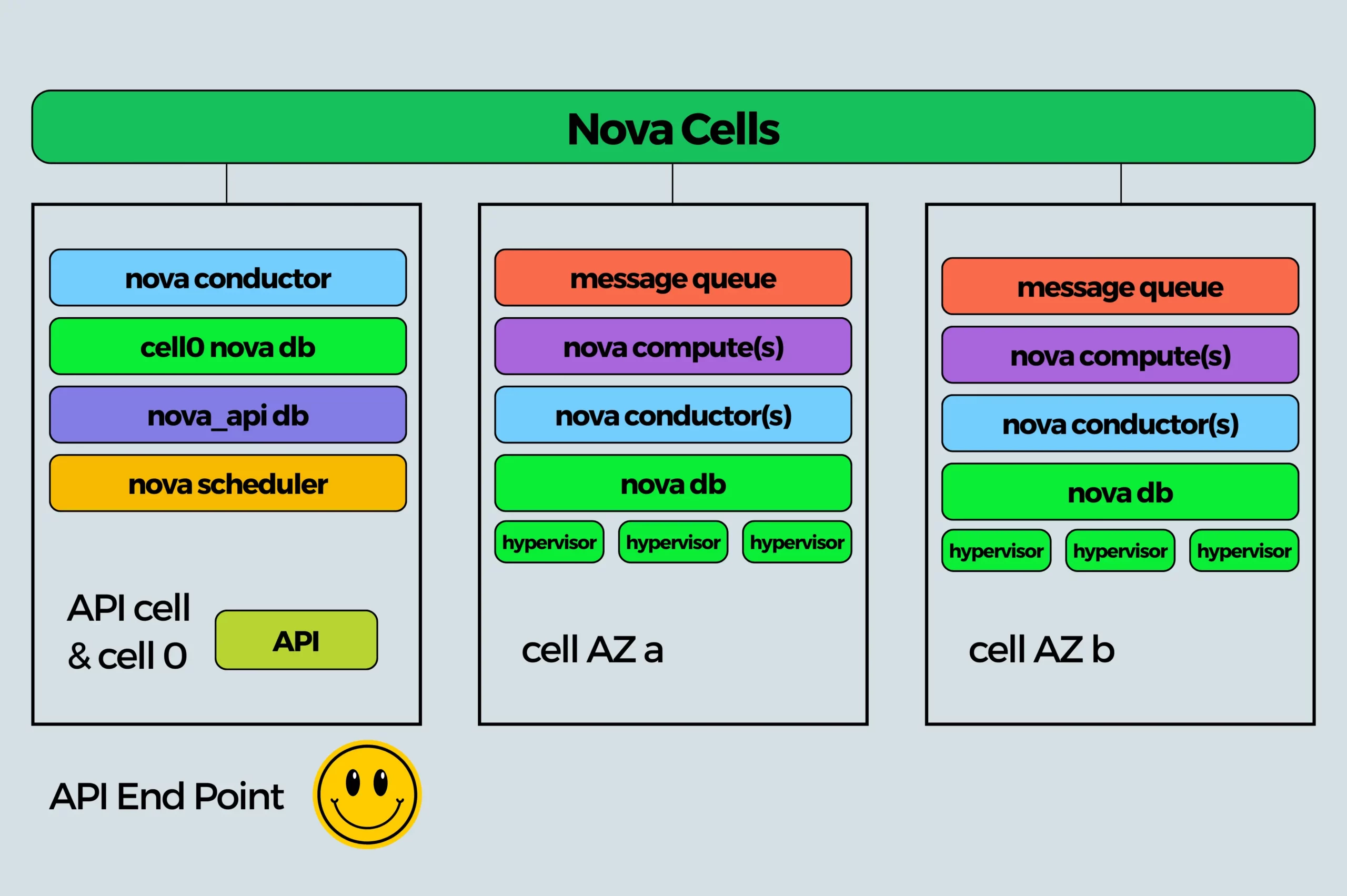
This design as illustrated above leads to higher availability, lower risk, and better control over scaling.
When Should You Use Nova Cells?
Nova Cells as design concept are mandatory in modern OpenStack releases, but when should you add additional cells beyond the default?
You should consider using multiple cells when:
- Your deployment has 100 or more compute nodes
- You’re managing multiple data centers or availability zones
- You want fault tolerance between infrastructure zones
- You need performance at scale by reducing load on the main Nova DB and message bus
For small deployments (under 50 – 100 nodes in one location), one default cell (plus cell0) is usually sufficient.
Single Cell vs Multiple Cells in OpenStack Nova
When deploying OpenStack, you’ll always have at least one default cell (plus the special cell0), but choosing whether to stick with a single cell or expand to multiple cells depends on the scale, architecture, and operational goals of your cloud.
Here’s how the two approaches compare:
| Feature | Single Cell | Multiple Cells |
|---|---|---|
|
Compute Scale |
Suitable for small to medium environments (e.g., <100 compute nodes) |
Ideal for large-scale environments (100+ compute nodes) |
|
Fault Isolation |
Limited — issues can affect the entire compute plane |
Strong — failure in one cell doesn’t impact other cells |
|
Database Load |
All compute nodes share the same database and MQ |
Each cell has its own database and MQ, reducing chance of contention |
|
Geographic Distribution |
Typically one location or rack |
Supports distributed data centers and availability zones |
|
Operational Complexity |
Simple to set up and manage |
More complex setup, requires cell registration in the main Nova DB and coordination |
|
API Layer |
Unified API, but all compute is in one backend |
Still a unified Nova API, but backend compute is logically separated |
|
Deployment Tools |
Works out of the box with most OpenStack installers |
Requires additional DB and message bus and setup with nova-manage |
You can start with a single cell during initial deployments. As your infrastructure grows – especially across locations or to hundreds of nodes – add cells to isolate fault domains and improve scalability.
IMPORTANT: keep in mind that reassigning compute nodes with VMs from one cell to another is not easily possible. If a compute node was first registered in cell 1 -> you cannot simply move it to cell 2 with all workloads.
Therefore, it is best to plan ahead how you would utilize the Cells as your cloud grows. Each new cell requires its own Nova conductor, database, and message queue. Tools like kolla-ansible or our own c12n.cloud support multi-cell deployments.
Deployment Tips
- Nova Cells are part of the default architecture since the Pike release, so you’re likely already using them – even if you don’t realize it.
- cell0 is required and used to track unscheduled/failed instances.
- Additional cells must be explicitly created and mapped using tools like nova-manage. The configuration will be written into the main Nova API database.
- Plan for independent scaling, monitoring, and fault recovery per cell.
- Consider running Nova API with its components across multiple AZs in addition to cells. The API and cell0 databases can be using the same DB instance replicated over all AZs.
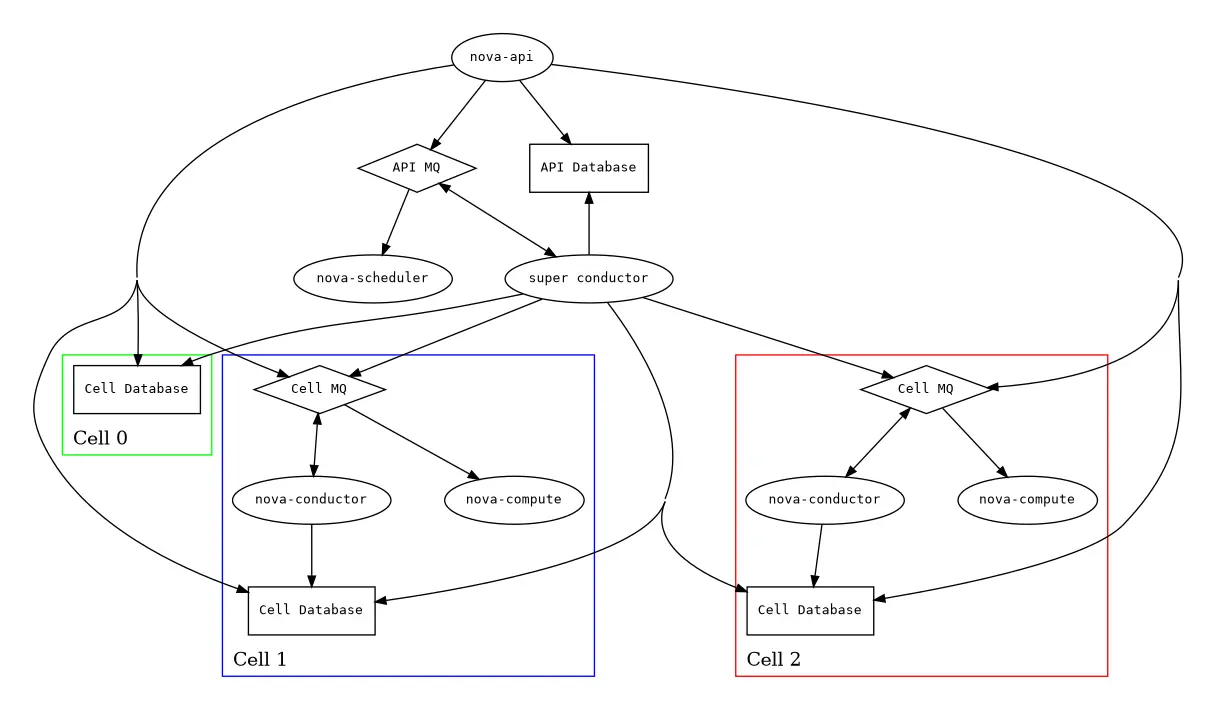
For the latest documentation about Nova cells – refer to the official OpenStack documentation.
Final Thoughts
OpenStack Nova Cells are a foundational design choice for any OpenStack deployment that needs to scale or span multiple physical locations. They provide better performance through distributed compute domains, increased resilience through fault isolation, logical separation of availability zones as well as a seamless, unified experience for end users.
If you’re running – or planning to run – a large or highly distributed OpenStack environment, Cells aren’t just a nice-to-have, they’re a must and you have to plan for those from the start as moving compute nodes between the cells is anything but easy.
At Cloudification, we help organizations build, scale, and modernize OpenStack clouds with best practices like Nova Cells, end-to-end GitOps automation and Kubernetes integration. Want to talk about scaling your cloud? Let’s chat.